0x531 Task
1. Information Retrieval
Classical lexical/statistical IR methods are summarized in the search engine note
1.1. Dense Retrieval
Model (ME-BERT) Multi-Vector Encoding
Model (ColBERT) late interaction
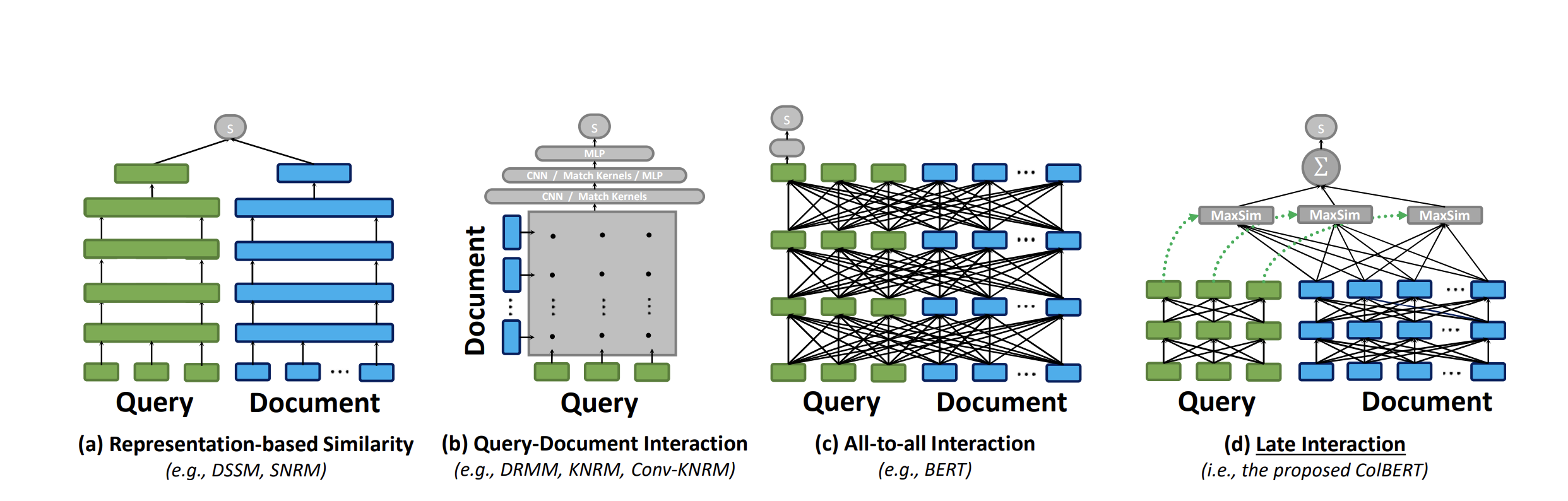
1.2. Reranking
1.3. Generation
Model (promptagator) leverages LLM as a few-shot query generator, and creates task-specific retrievers based on the generated data
Model (WebGPT) allows GPT to search/navigate the web
- Behavior cloning
- Reward Modeling
- Reinforcement learning
- Rejection sampling

2. Translation
Model (Google translation 2017)
Model (knowledge distillation) Distill knowledge from multiple teacher (trained with each lang-pair data separately) to a single multilingual student. The loss is both NLL loss and distillation loss (cross entropy of student/teacher distribution)
Model (massively multilingual model)
Transfer vs Interference:
the goal is to achieve
- high transfer (positive transfer) to low-resource languages
- low interference (negative transfer) for high-resource languages.
Sampling strategy:
- original language distribution has low-transfer/low-interference
- equal sampling (by upsampling low-resource lang) has high-transfer/high-interference
- this work suggests using a temperature-based sampling has a good balance over transfer/inteference. Sampling prob is \(p_l^{1/T}\) where \(p_l\) is the original distribution and \(T=5\)