0x541 Decoder Model
1. Encoder-Decoder Model
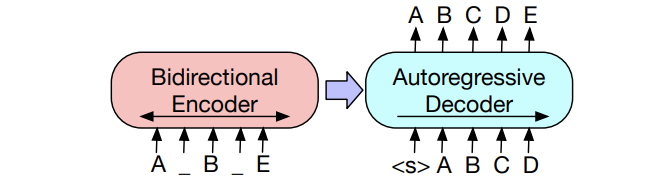
1.1. BART
Model (BART)
BART is a denoising encoder-decoder model trained by
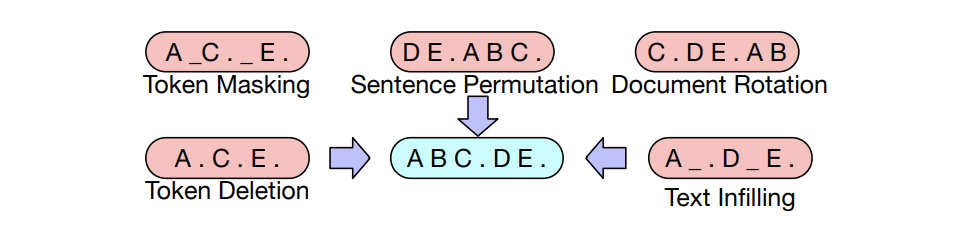
- corrupting text with noise
- learn a model to reconstruct the original text
BART noise are as follows
1.2. T5
Model (T5, Text-to-Text Transfer Transformer)
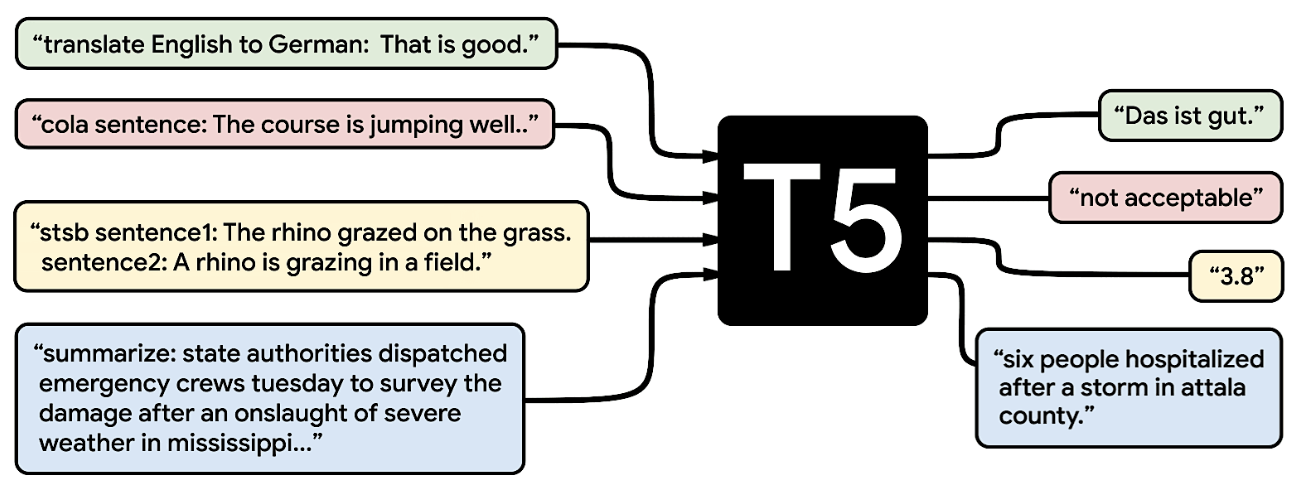
Also check the Blog
2. Decoder Model (Causal Language Model)
2.1. GPT
GPT is a language model using transformer. Check Mu Li's video
Model (GPT) 0.1B
Check the next section for details
Model (GPT2) 1.5B
Model (GPT3) 175B
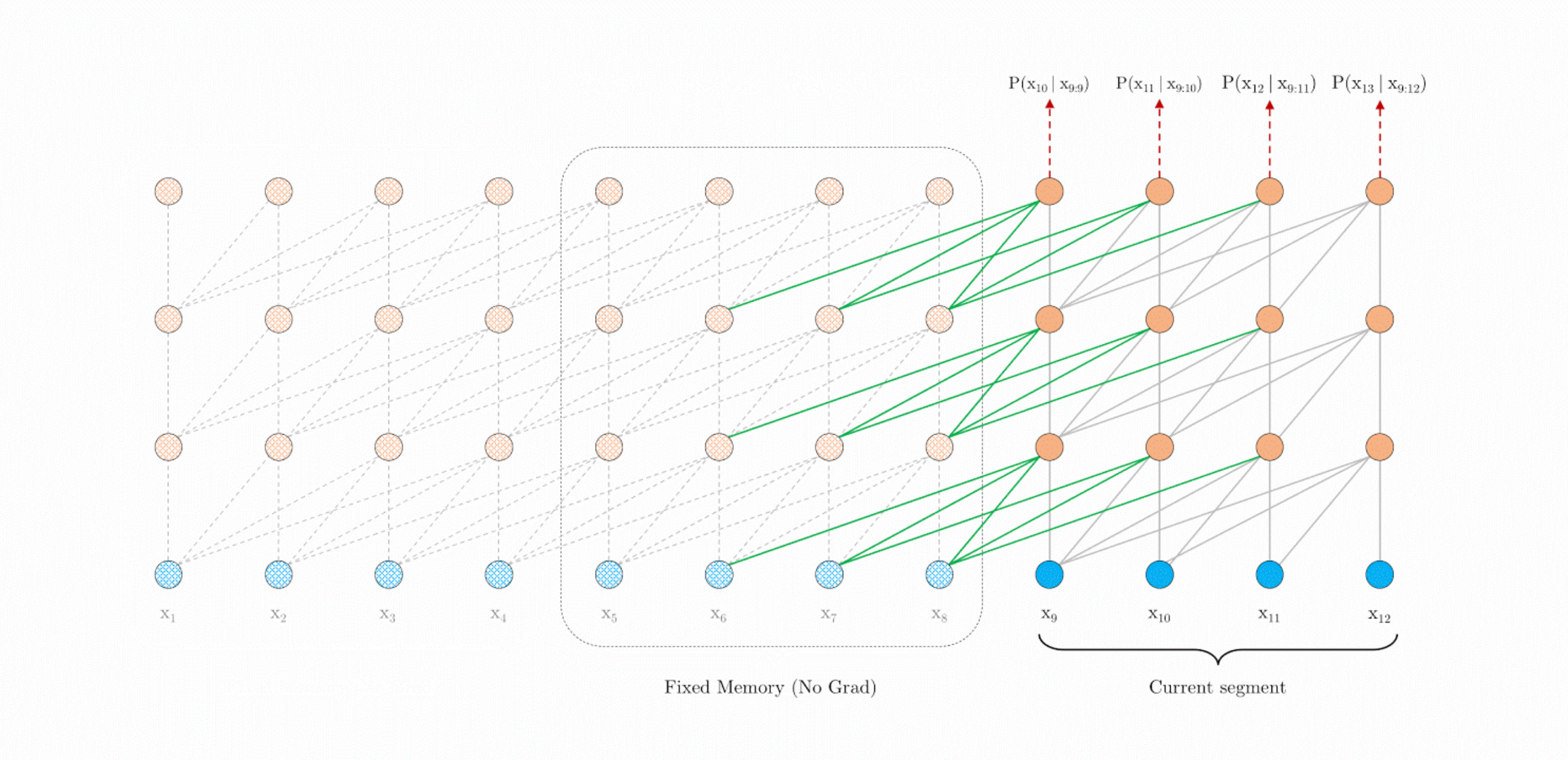
2.2. Transformer XL
Model (Transformer XL) overcome the fixed-length context issue by
- segment-level recurrence: hidden values of the previous segment is cached and provided to the next segment
- relative positional encoding: use fixed embedding with learnable transformation
See this blog
2.3. XLNet
Model (XLNet) Permutation language model
2.4. Distributed Models
Model (LaMDA) A decoder only dialog model
- pretrain on next word prediction
- fine-tuned using "context sentinel response" format
See this Blog
Model (PaLM, Pathway LM)
See this blog
3. Decoding
Naive ways to generate are
- greedy search: pickup the highest probability at each timestamp
- beam search: keep the top-k most likely hypothesis at each timestamp
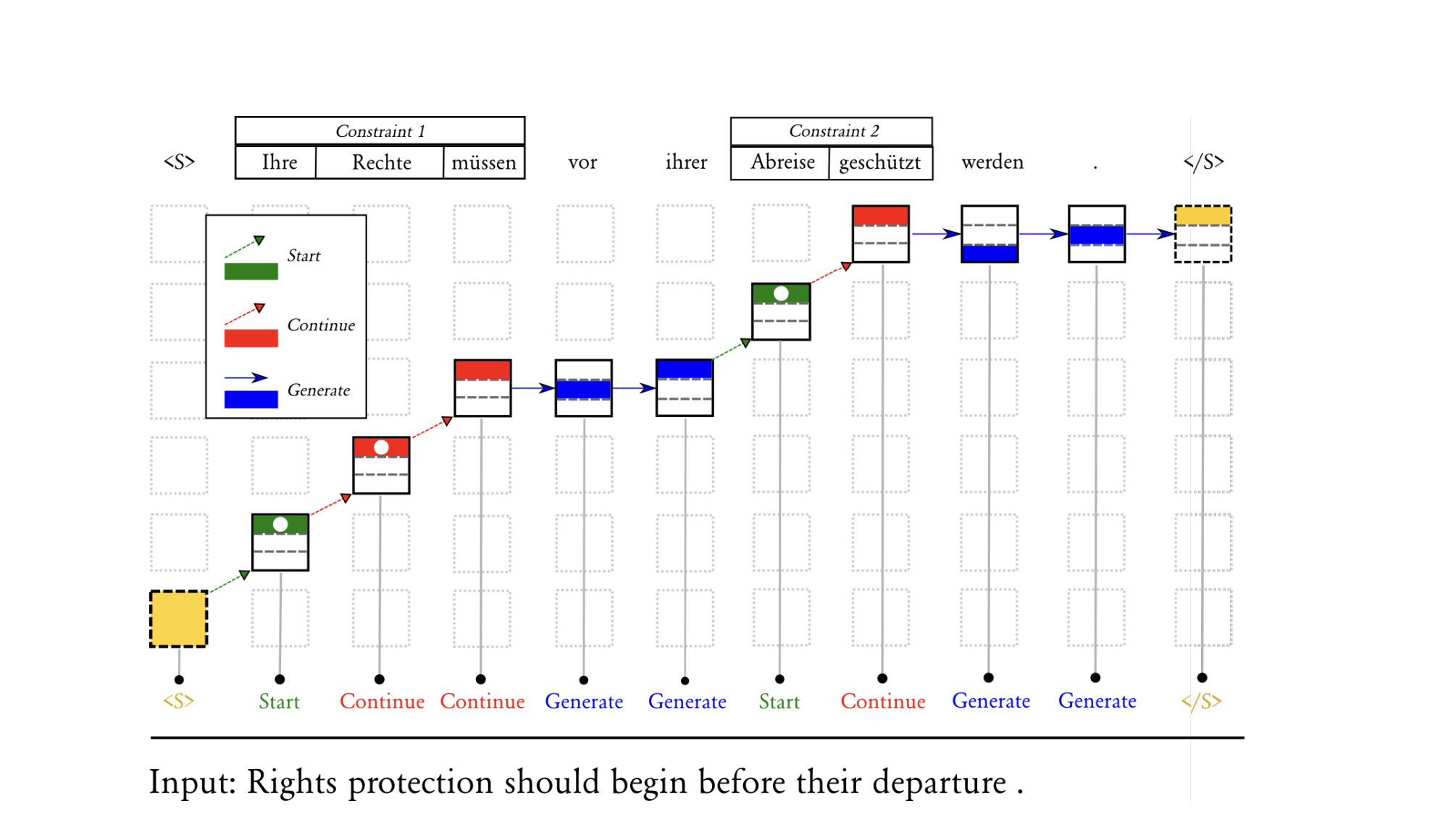
Model (grid beam search, lexical constraints) extend beam search to allow lexical-constraints with a new axis
check this huggingface blog
Model (nucleus sampling, top-p sampling) top-p sampling build the top candidates based on cumulative probabilities crossing a threshold:
then the probability mass is distributed within this set. Unlike a fixed top-k sampling, this is more adaptive to different distribution.
Model (speculative decoding) sample an episode from a small model of \(q(x)\) and use the correct (large) \(p\) to decide which timestep to cut off
Model (Jacobi decoding) iteratively decode the entire sequence until convergence. This can be enhanced by combining with n-gram trajectory, lookahead decoding
4. Analysis
4.1. Scaling
Check this lecture series
Analysis (do you need billions of words of pretraining data) LM requires only 10M or 100M words to learn syntactic/semantic features, a much larger datase (1B, 30B) t is required to acquire common sense knowledge
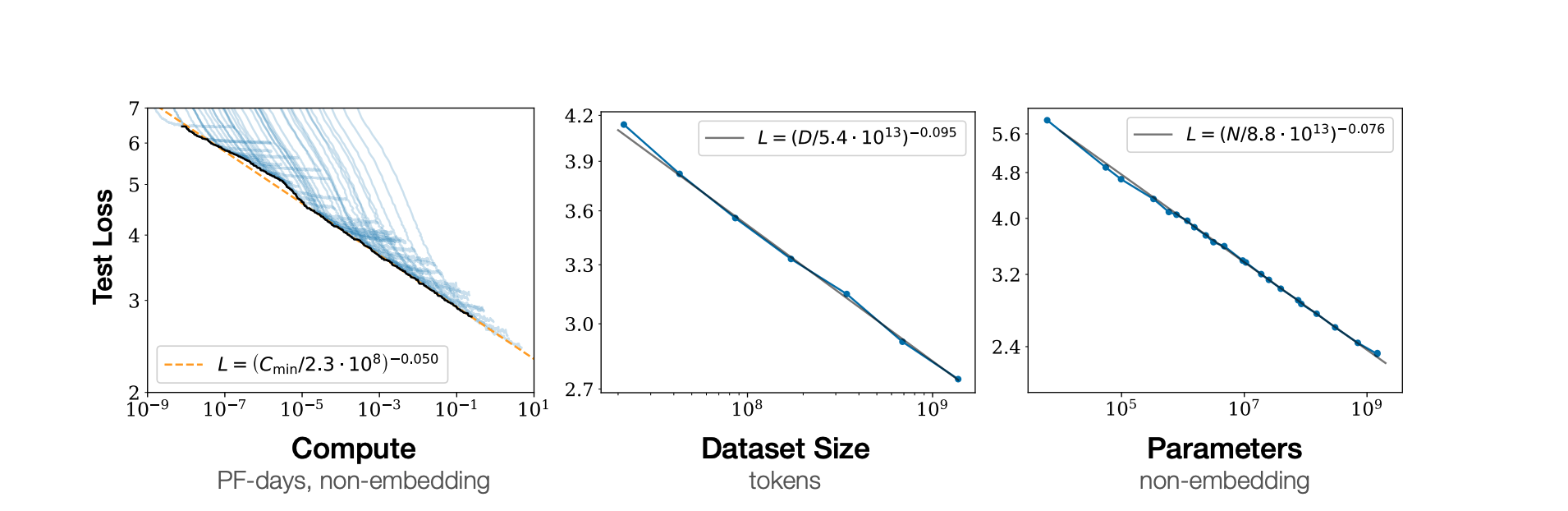
Analysis (scaling, scaling laws for neural language model) cross-entropy loss scales as a power-law wrt model size, dataset size, computation size:
Aanalysis (U-shape scaling) there are a few tasks that has worse performance with larger models, those tasks, however, actually have the U-scaling curve, where the decreased performance with medium model might be explained by the "distractor task"
4.2. Calibration
Model (confidence calibration) the probability associated with the predicted class label should reflect its ground truth correcteness
Suppose the neural network is \(h(X) = (\hat{Y}, \hat{P})\), where \(\hat{Y}\) is the prediction, \(\hat{P}\) is the associated confidence, a perfect calibration should satisfy
A measurement of calibrartion is ECE (Expected Calibration Error) defined as the difference between confidence and actual probability
Analysis (larger models are well-calibrated) larger models are well-calibrated in the right format