0x363 Storage
1. Storage Model
A DBMS's storage model specifies how it phyiscally organizes tuples on disk and in memory.
It has different performance characteristics based on the target workload (OLTP vs OLAP)
1.1. Row Model (N-ary Storage Model)
Row-oriented model:
- stores (almost) all attributes for a single tuple contiguously in a single page (e.g. 4KB page size)
- ideal for OLTP worklads
- fast read
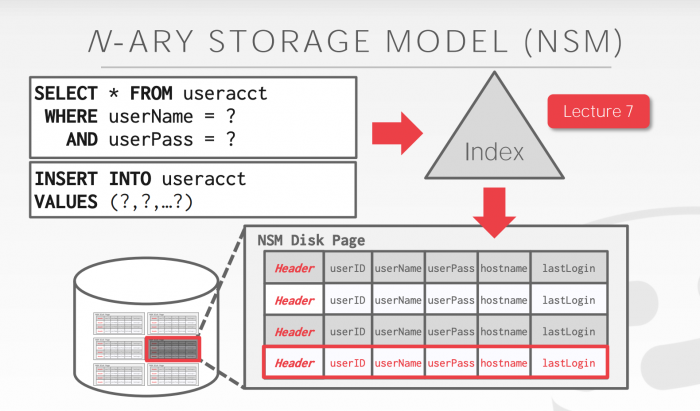
1.1.1. Layout
Each page contains a header (page size, checksum, version...).
There are two types of layouts:
- page oriented layout
- log-structured model
Tuple-Oriented model, usually associated with B-Tree
Pros:
- fast read
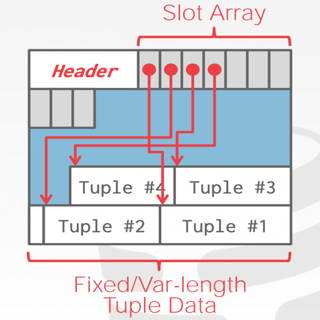
Slotted Tuples
Log oriented layout appends the new log to pages (hbase, cassandra, leveldb ...)
Pros:
- fast write
The most popular modell is the LSM-Tree + SSTable
SSTable (Sorted String Table): requires the key-value pair be sorted by key in each segment.
LSM-Tree LSM-Tree's storage stores multiple SSTables
- When the memtable gets bigger than some threshold, we write it out to a disk as an SSTable
- from time to time, we merge and compact segments to discard overwritten values
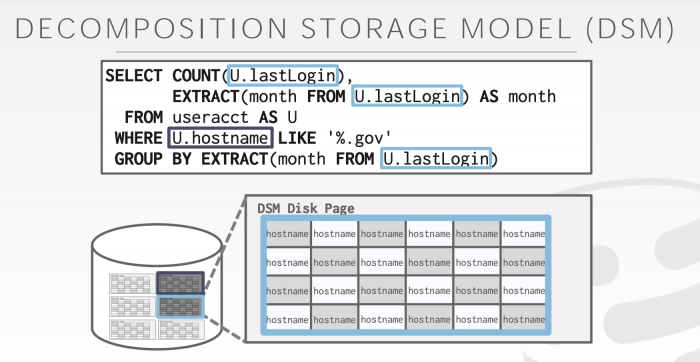
1.2. Column Model (Decomposition Storage Model)
Column Model:
- stores the values of a single attribute for all tuples contiguously in a page
- Ideal for OLAP workloads where read-only queries perform large scans over a subset of the table’s attributes
Large value:
- make them into overflow page and store pointer
- make them into external file and store path
1.2.1. Compression
Column Compression
Sequences of values for each column is usually repetitive, so we can compress them using several compression techniques, compression can reduce memory bandwidth and help vectorize the processing
Compression techniques are for example:
- bitmap encoding: for each unique label, we store a bitmap
- run-length encoding: if the number of distinct label is very large, then the bitmap is sparse, which we can further use run-length encoding to compress
Compression Order
We can impose order to all rows using a column to improve processing efficiency and compression. Different column sorting can be done in different replications
1.3. Mixed Model
a mix of row-oriented model and column-oriented model:
Wide-column model:
- column-family are stored separately (as the col model does)
- but within column family, multiple columns are stored together (as the row model does)
BigTable
BigTable is a sparse multi-dimension map
Apache Parquet
See this twitter blog
2. Storage Management
One solution to manage storage is using file mapping (mmap), it works well for reading, but not good when there are multiple writers. Instead, database tends to manage storage by themselves using database pages (different page size for different db)
Heap File A heap file is an unordered collection of pages. There are two styles of heap file.
- Linked List: there is a header managing pointers to data pages and free pages
- Page Directory: track the location and free slots for each page