0x221 Computing
- 1. Foundation
- 2. Instruction-level Parallelism (ILP)
- 3. Data level Parallelism (SIMD)
- 4. Thread level Parallelism
- 5. Reference
1. Foundation
2. Instruction-level Parallelism (ILP)
2.1. Pipeline
2.2. Static Scheduling
by compiler
2.3. Dynamic Scheduling
by out-of-order execution
a good video on Tomasulo's alogrithm
2.4. Multiple Issue processors
superscalar processor The superscalar architecture implements parallelism within one core executing independent part of instruction from the same instruction stream. This was one of the main strategies in the pre-multi core era, but requires a lot transistors for cache, branch predictor, out-of-order logics. P5 Pentium was the first x86 superscalar processor.
The following example shows a single-core architecture which can execute two independent instructions simultaneously from a single instruction stream.
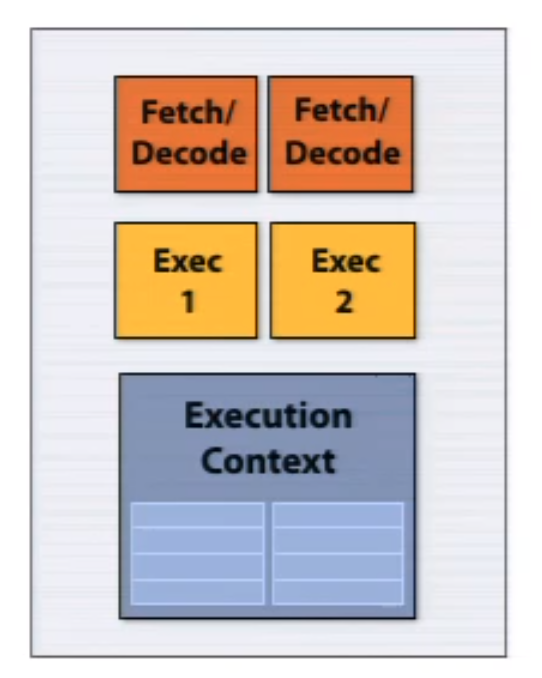
VLIW (very long instruction word) software (compiler) packs independent instructions in a larger instruction bundle and get executed in a lock step. Compiler need to understand arichtecture of hardware.
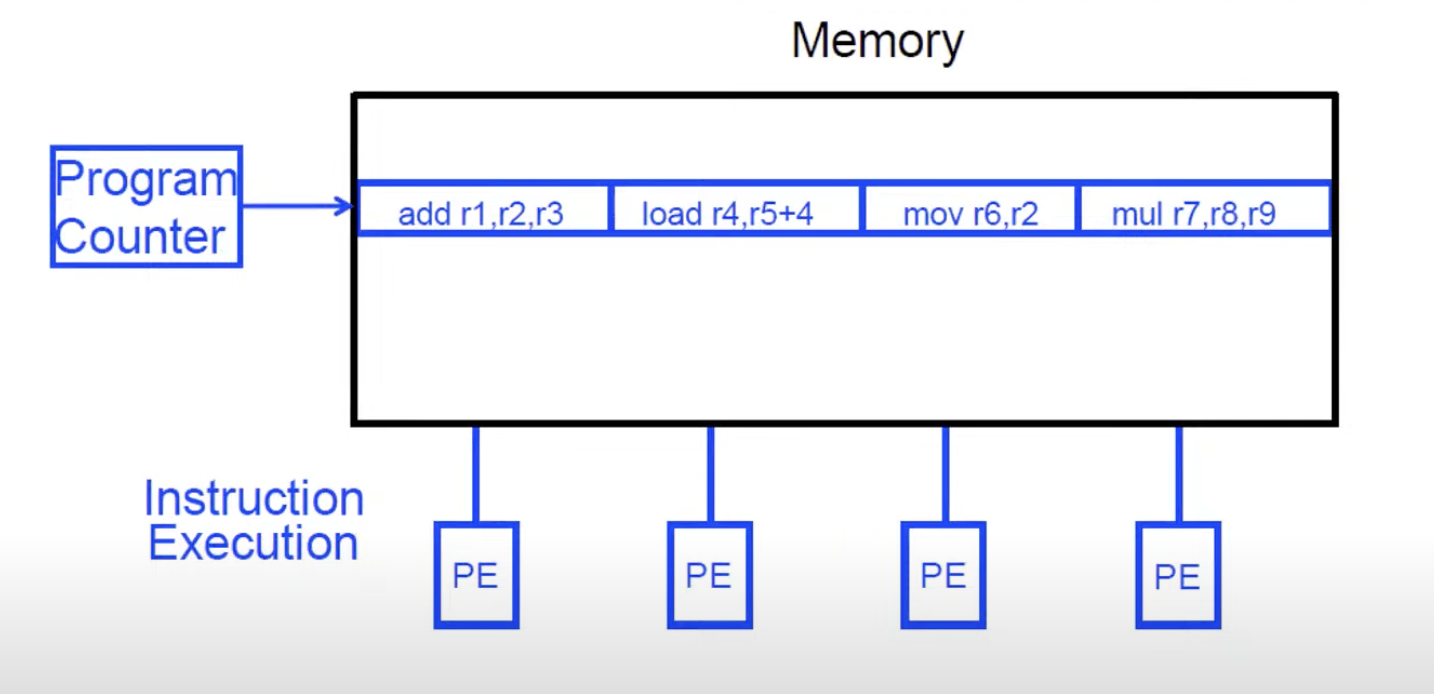
Advantages:
- No need for dynamic scheduling hardware
- No need for dependency check within a VLIW instruction
- No need for instruction alignment/distribution after fetch
Disadvantages:
- compiler need to find N independent operations per cycle (otherwise NOPs in a VLIW instruction inserted)
- recompilation required when execution width, instruction latencies changes
3. Data level Parallelism (SIMD)
Two examples:
- array processor
- vector processor
MMX was originally proposed in this paper, which is a nice reading with MMX's applications to matrix-vector and chroma keying
MMX:
- 64 bit MMX registers for integers (e.g. PADD)
SSE (Streaming SIMD Extensions)
- SSE-1: 128 bit XMM registers for integers and float
- SSE-2: double
- SSE-3: new instructions
- SSE-4: new instructions, shuffle operations
AVX:
- AVX: 256-bit floating point
- AVX2: 256-bit floating point with FMA (fused multiply add)
- AVX-512: 512 bit
AMX (advanced Matrix Extensions)
- designed for AI/ML workloads
- 2-dimensional registers
- tiled matrix multiply unit (TMUL)
4. Thread level Parallelism
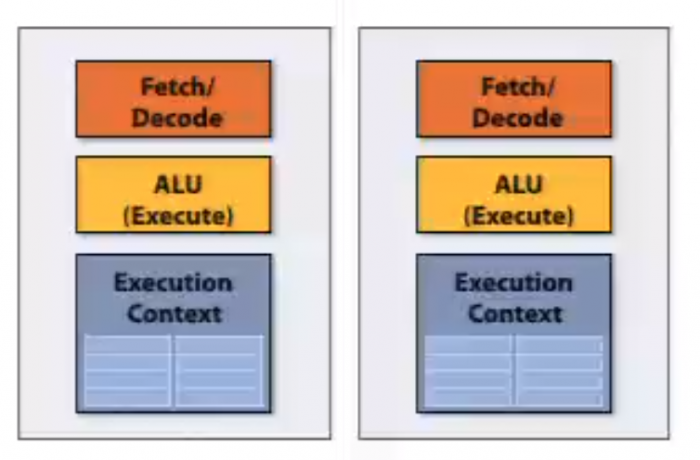
hyper-threading: super-scalar with multiple execution contexts in a single core
multi-core: thread-level parallelism. simultaneously execute a completely different instruction stream on each core
5. Reference
[1] Patterson, David A., and John L. Hennessy. Computer Organization and Design ARM Edition: The Hardware Software Interface. Morgan kaufmann, 2016.
[2] Hennessy, John L., and David A. Patterson. Computer architecture: a quantitative approach. Elsevier, 2011.
[3] CMU 15-418/15-618: Parallel Computer Architecture and Programming
[4] CMU 18-447 Introduction to Computer Architecture
[5] CSAPP