0x360 Foundation
1. Data Model
A data model (or datamodel) is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities
1.1. Relational Model
Relational Model is a data model representing data with unordered set of tuples.
A relational database contains a set of named relations (or tables) Each relation has a set of named attributes (or columns) Each tuple (or row) has a value for each attribute, tuples in the relation is not ordered. Each attribute has a type (or domain)
The schema is the formal description of relations in database, it is something like typing in programming languages.
Instance is the actual contents at given point in time There is a special value NULL for unknown and undefined, which is important in relational database.
Key is an attribute whose value is unique in each tuple or set of attributes whose combined values ar unique. Keys are often denoted by underlining the set of key attributes. Relational database tends to build special index for keys to achieve efficiency.
There are two types of languages in relational model
- DDL (data definition language): create, drop
- DML (data manipulation language): select, insert
query relation model
The steps in creating and using a relational database
- Design schema; create using DDL
- Bulk load initial data
- Repeat; execute queries and modificiations
Queries return relations (or table)
1.2. Hierarchical Model
Hierarchical Model or Document Model represent all data as a tree structure. It worked well for 1-to-Many relationships, but it made many-to-many relationships difficult.
To handle n-n relationships, we can
- denormalize the data (duplicating)
- resolve the join inside the application.
1.2.1. XML
XML (Extensible Markup Language) is a standard for data representation and exchange. XML has more flexibility when compared with the relational model.
The basic constructs of XML
- tagged elements, which can be nested
- attributes
- text (can be thought as the content for the leaf node)
1.2.1.1. DTD/XSD
A well-formed XML adheres to basic structural requirements
- single root
- matched tags, no open tags
- unique attributes within elements
A valid XML adheres to the basic structral requirements and also content-specific specification Examples to describe the specification are
- Document Type Descriptor (DTD)
- XML Schema (XSD)
The specification can be provided to the XML parser to decide whether the XML is valid or not. For example, xmllint can be used to verify.
Document Type Descriptor (DTD) DTD is a grammar-like language for specifying elements, attributes, nesting, ordering, occurrences It also has special attribute types such as ID and IDREF(S), which works like the pointers
XML Schema (XSD) In addition to the DTD feature, XSD also sepcifies data types, keys, pointers. It is also written in XML.
1.2.2. JSON
JSON is a stanrdard to serialize data objects into human readable format, it is useful for data interchange, and representing & storing semistructured data.
1.3. Network Model
The network model represents data using a graph structure. Link between records in the network model are like the pointers in the programming languages. It was standarized by CODASYL.
Querying network need to follow a path from the root designed manually.
2. Serialization
Programs usually work with data in two formats:
- in memory, data is kept in objects, which are optimized for efficient access of GPU by using pointers
- in file disk/network, data has to be encoded into a sequence of bytes
The translation from object to byte sequence is called encoding, or marshalling or serialization.
Language-Specific Format
Many languages support its own encoding features
- Java: java.io.Serializable
- Ruby: Marshal
- Python: pickle
They are convenient but has the following problems
- not portable across languages
- security issue to instantiate any class
- data-versioning issue (i.e backward/forward compatibility)
2.1. Row-Oriented Format
There are binary encoding for JSON such as MessagePack, but the encoding is still not very efficient. Compact binary encoding such as Protocol Buffer are better in the inter-organization communication
Protocol Buffer is a language-neutral, platform-neutral extensible mechanism for serializing structured data.
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
It has the following benefits:
- compact: field name string is omitted by replacing it with a field tag number
- compatibility: backward/forward compatibility can be achieved by paying attention to the tag number
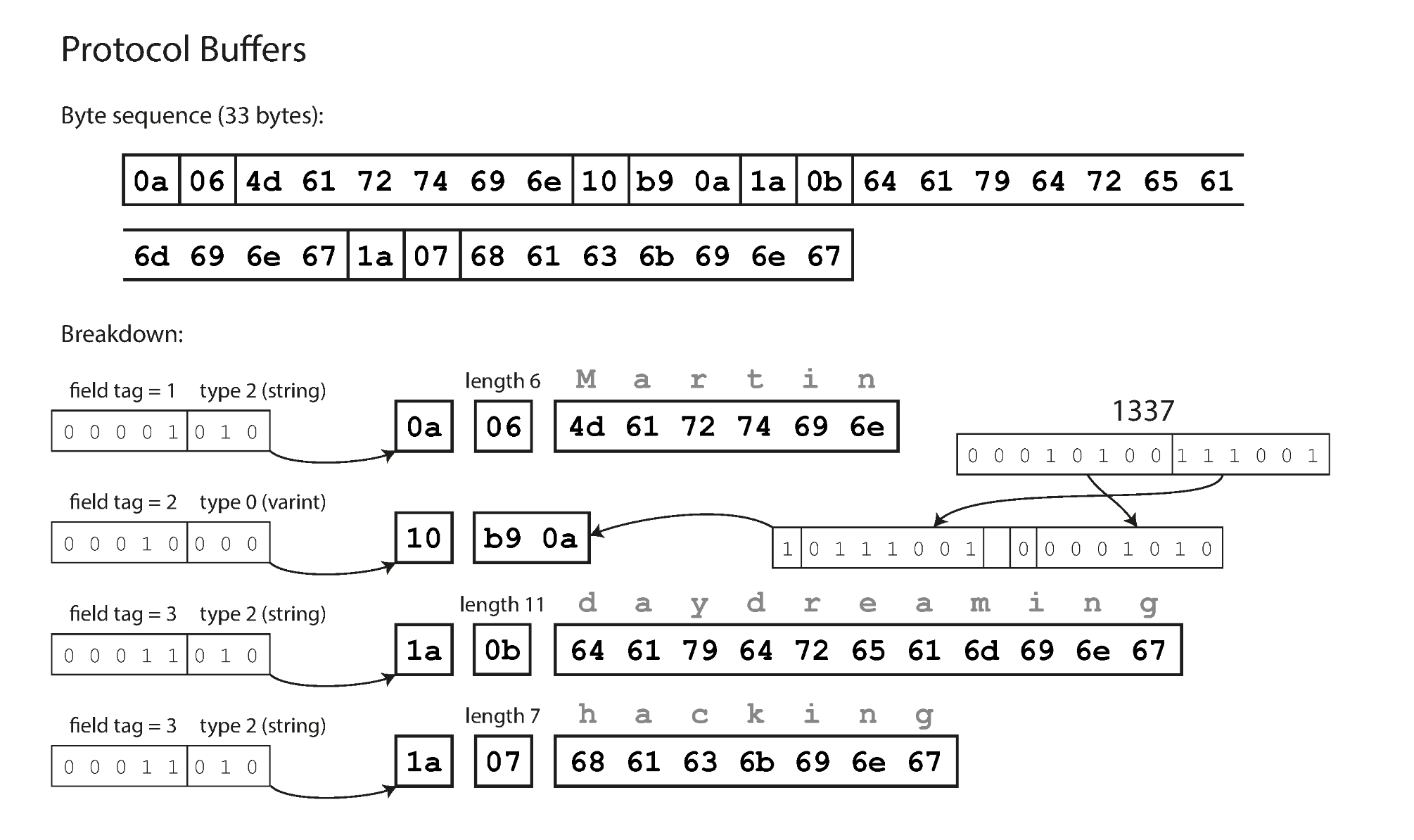
See the following python snippet for converting between object, binary and string.
address_book = addressbook_pb2.AddressBook()
# encode object into binary
with open("address_book.pb", "wb") as f:
f.write(address_book.SerializeToString())
# decode from binary into object
with open("address_book.pb", "rb") as f:
# either of the following
address_book.ParseFromString(f.read())
address_book = addressbook_pb2.AddressBook.FromString(f.read())
from google.protobuf import text_format
# encode object into string
with open("address_book.pbtxt", "w") as f:
f.write(text_format.MessageToString(address_book))
# decode string into object
with open("address_book.pbtxt", "r") as f:
text_format.Parse(f.read(), address_book)
There are a few other similar formats such as Avro and Thrift
2.2. Column-Oritend Format
Apache Parquet (Capacitor)
3. Communication (IPC)
The lowest level IPC on Windows is done by COM (component object model). On Linux, there are two families of IPC: System V IPC and POSIX IPC. POSIX IPC is a newer one and thread safe, but sometimes not supported in some OS.
3.1. System V IPC
3.2. POSIX IPC
3.2.1. Pipe
Pipes are the oldest method of IPC (from Version 3 Unix). A pipe is an undirected byte stream (random access (e.g.: lseek) not allowed. However, pipe looks not supported in recent Zircon microkernel
Writes of up to PIPE_BUF (4096 in Linux )bytes are guaranteed to be atomic. buf size can be modified with fcntl (up to about 1M in Linux). this would help reduce context switch
API (int pipe(int filedes[2]) (2))
filedes[0] is the read end, filedes[1] is the write end. If all write fds are closed, then all read fds receives EOF
Normally pipe is followed with fork and the child process imherits copies of parent's fds. Usually one closes the read end, and the other closes the write end.
Bidirectional IPC can be implemented with two pipes
close unused pipep fd is important.
If redundant write fds are not closed, then read fd cannot receive EOF correctly.
If redundant read fds are not closed, then write fd cannot receive SIGPIPE signal
3.3. Windows IPC
Windows has following IPC mechanism
- Clipboard,
- COM
- Data Copy
- DDE
- File Mapping
- MailSlot
- Pipes
- Windows Socket
- RPC
3.3.1. COM IPC
In my personal understanding, COM is doing following things equivalent in linux
- fork a process
- open pipe to share message binary memory
- construct object over binary (COM interface defines how to construct obj) and manage its life
- close the process
3.3.2. WinRT IPC
wrapper of COM