0x302 Information Theory
Foundation
Information Theory is concerned with representing data in a compact fashion, the most important concepts are summarized here
Definition (entropy) The entropy of a discrete random variable \(X\) with distribution \(p\) is
For a K-ary random variable, the maximum entropy is \(H(X) = \log K\) when \(p(X=k) = 1/K\)
Definition (differential entropy) The continuous version is the differential entropy.
Note this differential entropy is not the exact generalization of the discrete version, the actual generalization is called LDDP
entropy of Gaussian
For a univariate Gaussian variable
then its entropy is
For a multivariate Gaussian variable,
then its entropy is
Definition (relative entropy, KL divergence) One way to measure the dissimilarity of two probability distribution \(p, q\) is the Kullback-Leibler divergence (KL divergence) or relative entropy
KL divergence is the average number of extra bits needed to encode the data \(p\) with distribution \(q\).
Definition (cross entropy) \(H(p,q)\) is called cross entropy, it is to measure the average number of bits to encode data of distribution \(p\) using codebook of distribution \(q\), it is defined as
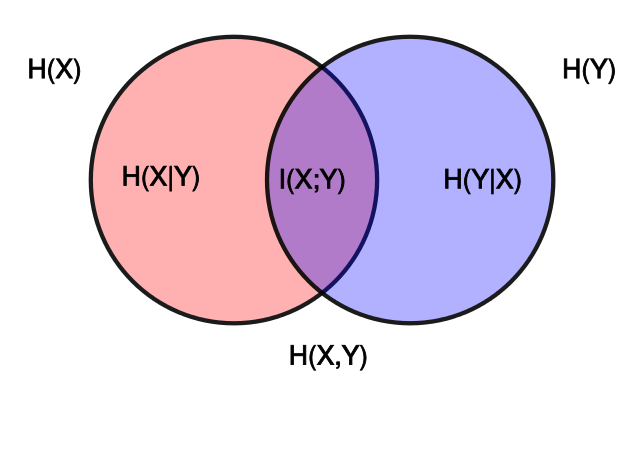
Definition (conditional entropy) The conditional entropy \(H(Y|X)\) is defined as
It can be re-written as:
Definition (mutual information) Mutual information or MI is an approach to estimate how similar the joint distribution \(p(X,Y)\) can be factored into \(p(X)p(Y)\)
Obviously, MI is zero iff two random variables are independent.
MI can be expressed using entropy as follows
example of Gaussian
Let \((X,Y)\) be 0 mean and \(\rho\) correlation, then its mutual information is
Therefore, MI can be interpreted as the reduction in uncertainty about \(Y\) after observing \(X\)
Statistics based on MI might capture nonlinear relation between variables that can not be discovered by correlation coefficients.
Model (mutual information neural estimator) Estimating mutual information is not easy, it can be done using neural network by optimizing
using samples of \((x,z)_n\). It is justified by the
Definition (pointwise mutual information) A related concept is pointwise mutual information or PMI, this is about two events \(x,y\)
Reference
[1] Cover, Thomas M., and Joy A. Thomas. Elements of information theory. John Wiley & Sons, 2012.