0x372 Database
Single-machine db models is written in the database note
1. Replication
1.1. Single-Leader Replication
This is used in many relational database such as PostgreSQL, MySQL, MongoDB.
The work flow is illustrated as follows (from DDIA book)
- one replicas is designated the leader, it will accept all writes requests and write them to its local storage
- leader sends the data change to followers as a replication log or change stream
- each follower updates its own database accordingly
- each replicas can serve read requests
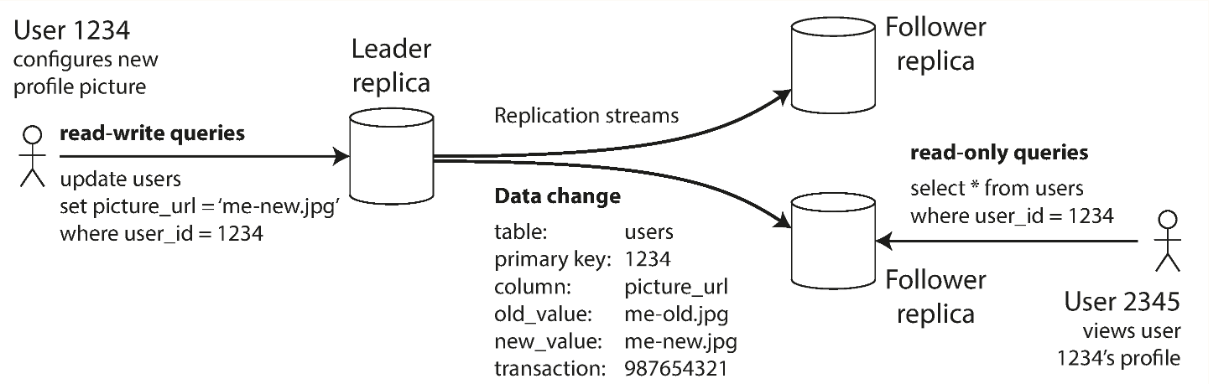
Replication can be done
- synchronous: guarantee each follower have an update-to-date copy (high durability), but if they do not respond, then the write will be blocking and cannot be processed (low availability)
- asynchronous send the log without waiting the response. Usually, leader-based replication is configed to be completely asynchronous.
- semi-synchronous: some followers are synchronous and some are not, see mysql's doc
1.2. Multi-Leader Replication
1.3. Leaderless Replication
In the leader-based replication, client sends a write request to only one node. In the leaderless replication, client sends both read/write requests to multiple nodes.
This idea becomes popular after Dynamo, which inspires Riak, Cassandra and Voldemort.
Concept (Quorum) Suppose there are \(n\) replicas and we write to \(w\) nodes and read from \(r\) nodes. If we have \(w+r > n\), then we can guarantee at least one copy will contain the non-stale value
2. Partitioning
3. Transaction
4. Case Studies
This section collects some articles about some actual systems deployed globally.
4.1. HBase (BigTable)
HBase (BigTable) is a sparse multi-dimension map
It is built on Colossus (Google File System), Chubby Lock Service, SSTable (log-structured storage like LevelDB) and a few other Google technologies
4.1.2. Data Model
- fast access to a row with an unique key
- each row has a small number of column family
- a column family can have multiple columns (can be very large number, can be sparse)
- each cell can have multiple versions indexed by timestamps
4.1.3. Applications
The following table is a row example from Bigtable paper, the anchor column family is used to compute page ranks.
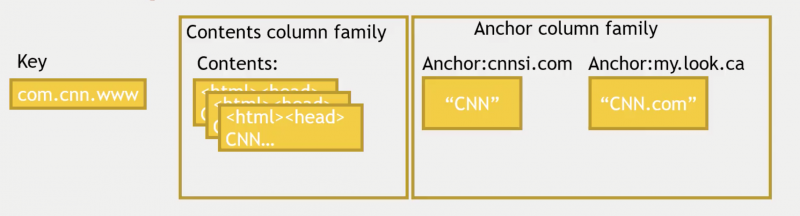
Reference: The Ultimate Hands-on Hadoop Chapter 6
4.2. BigQuery (Dremel)
Model (Dremel) Dremel is a scalable, interactive ad-hoc query system for analysis of read-only nested data.
4.3. Cassandra (Dynamo)
Cassandra (dynamo) has no master node
- High Availability, High Partition Tolerence
- Low Consistency (Eventual Consistency)
4.3.1. Interface
- CQL (something like limited SQL)
4.3.2. Architecture
- Replication: Consistent Hashing
- membership: Gossip-based protocol
5. Reference
- [1] Tanenbaum, Andrew S., and Maarten Van Steen. Distributed systems: principles and paradigms. Prentice-Hall, 2007.
- [2] system design primer
- [3] AWS scaling lecture
- [4] system design interview
- [5] CMU lectures
- [6] dropbox
- [7] 1PB sort with mapreduce