0x503 Reinforcement Learning
- 1. Prediction Approximation
- 2. Control Approximation
- 3. Reward Approximation
- 4. Policy Approximation
- 5. Reference
The actual problems in RL have large number of state spaces, which requires large memory and computation when using tabular based approach. We would like to use approximated models to generalize our observations.
1. Prediction Approximation
We use \(\hat{v}(s, w) \sim v_\pi(s)\) where \(\hat{v}\) is any approximated model parameterized with \(w\)
2. Control Approximation
3. Reward Approximation
Defining or obtaining a good reward function might be difficult, we want to learn it instead
3.1. Demonstration
In typical RL, we learn \(\pi\) from \(R\), but here we learn \(R\) from \(\pi\)
Model (inverse RL) inverse RL is defined to be the problem of extracting a reward function given observed optimal behavior.
Suppose we know the state, action space and transition model. Given a policy or demonstrations, we want to find reward \(R\)
Here is a lecture slide
Offline IRL is to recover the rewards from a fixed, finite set of demonstrations.
Model (max entropy) recover the reward function by assigning high rewards to the expert policy while assinging low rewards to other policy based on the max entropy principle
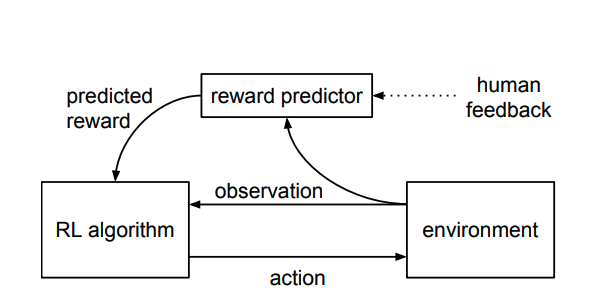
3.2. Human Feedback
Model (human preference model) solving tasks that human can only recognizes the desired behavior instead of demonstrating it
The reward is first trained using human ranking instead of ratings.
Those rewards are fed to the RL algorithm
4. Policy Approximation
4.1. Vanilla Policy Gradient
4.2. Trust Region Policy Optimization
Constraining the gradient update using KL-divergence
4.3. Proximal Policy Optimization
PPO also improves the training stability by avoid taking too large policy updates
5. Reference
[0] RL book 2nd
[1] OpenAI doc