Dissertation
My main research goal within my phd period was to create speech recognition systems for all the languages in the world (around 8k languages).
As most of the languages do not have any training set (and even test set), it is impossible to create any end-to-end models directly. Instead of building the end-to-end models, I am interested in decomposing the entire model into a sequence of linguistic components as the following pipeline shows, it has many advantages over the end-to-end models:
- some of the components here are relatively less dependent on training resources (e.g: texts are easier to obtain than audios)
- some of them are already well-defined by linguists (e.g: phonetics, phonology), those domain knowledge can be incorporated into the model through some Bayesian frameworks.
- language-wise interpolation is easier sometimes (e.g: English and German shares many common phones)
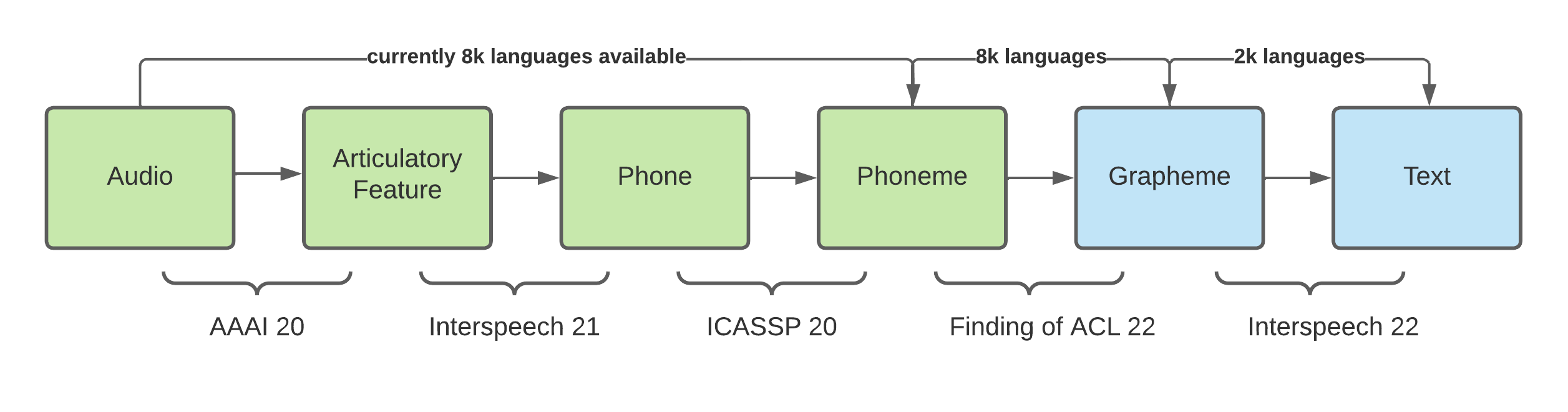
We have already worked on the green part in the last few years and published a few papers. This part has already been open-sourced at Github.
We hope to tackle the blue components and connect all lines to publish a general model to inference speech recognition for all languages.