0x514 Infrastructure
implementations and deployment of large DL models.
1. Scheduler
1.1. Single-controller
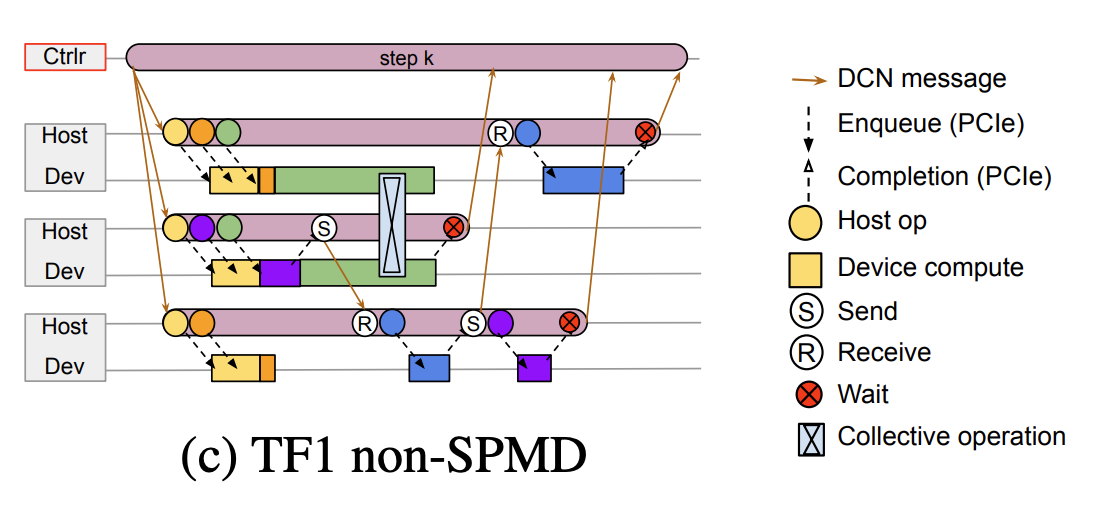
1.1.1. TF1
Traditional TF1 Single-controller uses a client to build graph and hands it off to coordinator runtime, which partitioned the graph into subgraphs for each worker and delegate execution to each worker runtime. It has flexibility but has dispatch latency.
It, however, accumulates latency with synchronous dispatch, it also lacks a centralized scheduler, thus impossible to ensure consistent ordering between computations across programs.
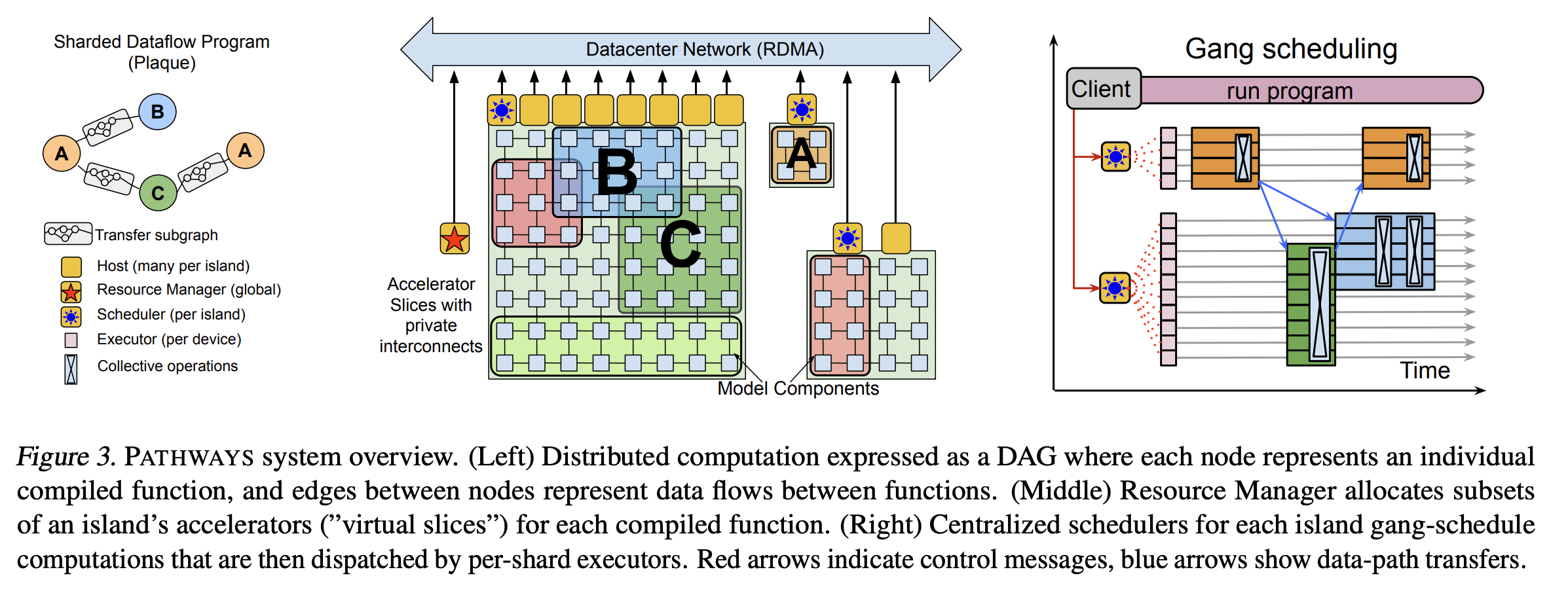
1.1.2. Pathway
Pathways (Barham et al., 2022)1 single-controller offers
- asynchronous dispatch to solve the latency issue
- centralized resource management
- shareded dataflow system
See the following code:
- pathway client may request sets of virtual devices satisfying constraints on device types, locations and topology
- functions (e.g. a, b, c in the following code) are compiled into XLA computations as usual
- tracing multiple compiled function into a single pathway program, then execute this program through pathway client
def get_devices(n):
"""Allocates `n` virtual TPU devices on an island."""
device_set = pw.make_virtual_device_set()
return device_set.add_slice(tpu_devices=n).tpus
a = jax.pmap(lambda x: x * 2., devices=get_devices(2))
b = jax.pmap(lambda x: x + 1., devices=get_devices(2))
c = jax.pmap(lambda x: x / 2., devices=get_devices(2))
@pw.program # Program tracing (optional), which may call multiple compiled function
def f(v):
x = a(v)
y = b(x)
z = a(c(x))
return (y, z)
print(f(numpy.array([1., 2.])))
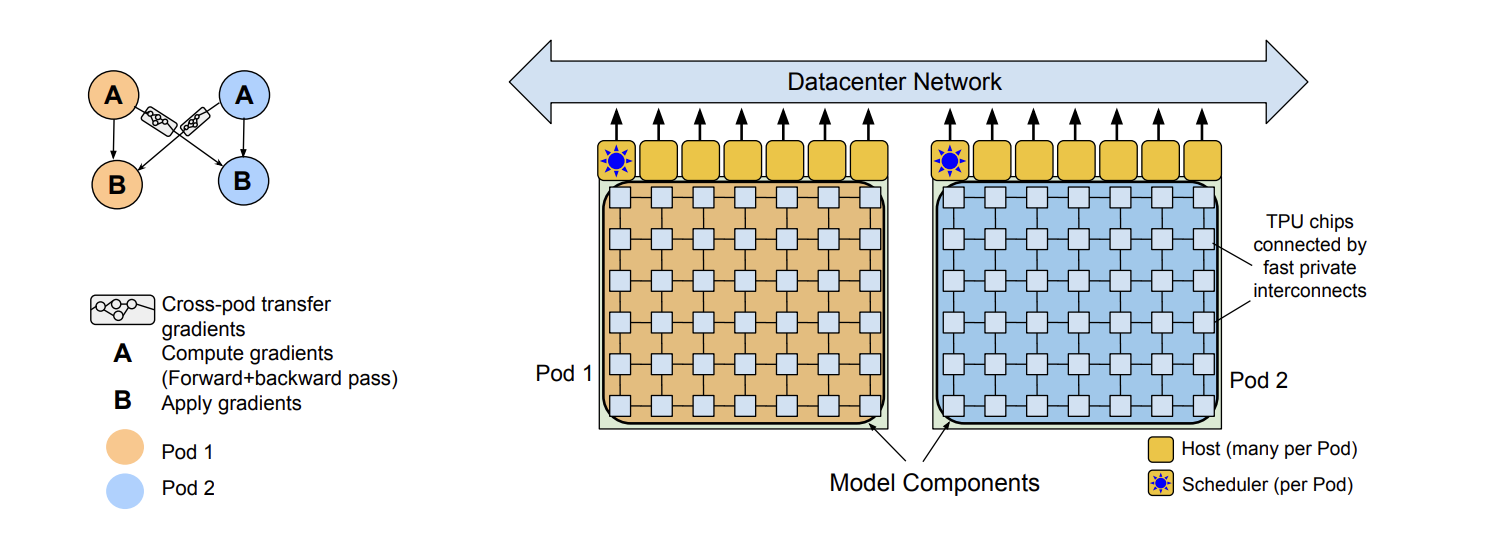
PaLM
PaLM (Chowdhery et al., 2023)2 is a language model implemented with Pathway with two-way data parallelism at the pod level
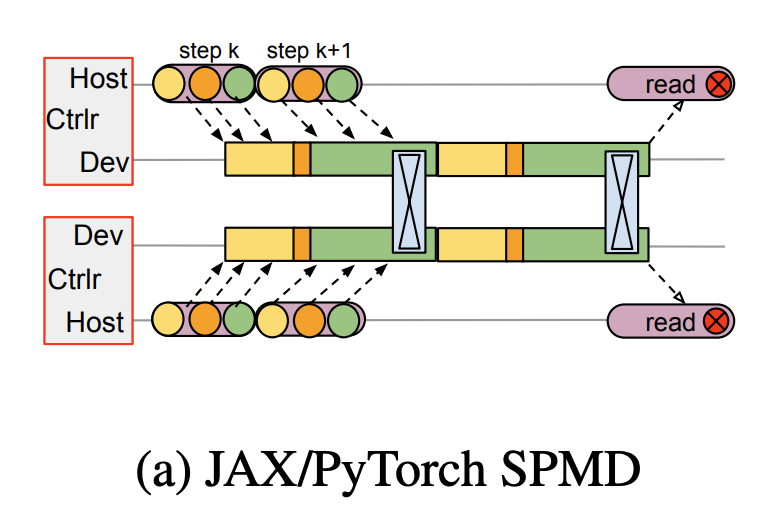
1.2. Multi-controller
Multi-controller architecture training with SPMD shares same executable on all hosts, each host maintain ownership of their resources.
This architectrue is low latency for dispatching kernels (because same executables are local to each host). but this architecture is poor for pipelining and computing sparsity
2. Serving
TF Serving
-
Paul Barham, Aakanksha Chowdhery, Jeff Dean, Sanjay Ghemawat, Steven Hand, Daniel Hurt, Michael Isard, Hyeontaek Lim, Ruoming Pang, Sudip Roy, et al. 2022. Pathways: Asynchronous distributed dataflow for ml. Proceedings of Machine Learning and Systems, 4:430–449. ↩
-
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113. ↩