0x502 Efficiency
1. Foundation
Some numbers about transformers, sadly, people only care about transformers these days.
With the following abbreviations
- B: batch size
- E: embedding size
- L: layer size
- H: number of hidden size
- N: number of heads
- V: vocab size
- T: target sequence length
- S: source sequence length
1.1. Paramter Estimation
The total number of parameters are roughly
- embedding layer: \(VE\)
- transformer layer: ~\(L(12E^2)\): out of 12, 4 are from QKVO, 4+4 are from 2 layer feedforward (note that layer norm parameter are ignored)
This gives a good estimation of GPT2's parameter
- 117M tiny: 12 layer + 768 dim + 50257 vocab (~124M)
- 345M small: 24 layer + 1024 dim + 50257 vocab (~353M)
- 762M medium: 36 layer + 1280 dim + 50257 vocab (~758M)
- 1542 large: 48 layer + 1600 dim + 50257 vocab (~1554M)
1.2. Computing Estimation
1.3. Memory Estimation
See this blog post
Model Memory Roughly in the inference, only 4 bytes per parameter is used, in the training 16 bytes (param + grad + 2 optimizer state) per parameter are used if not optimized.
The following detailed reference is from the Huggingface's transformer doc
Model Weights:
- 4 bytes * number of parameters for fp32 training
- 6 bytes * number of parameters for mixed precision training (maintains a model in fp32 and one in fp16 in memory)
Gradients
- 4 bytes * number of parameters for either fp32 or mixed precision training (gradients are always kept in fp32)
Optimizer States:
- 8 bytes * number of parameters for normal AdamW (maintains 2 states)
- 2 bytes * number of parameters for 8-bit AdamW optimizers like bitsandbytes
- 4 bytes * number of parameters for optimizers like SGD with momentum (maintains only 1 state)
Activation Memory Without any optimization, it will be roughly the following
- input+output: \(2BTV\) one-hot vector input/output (can be ignored compare the next)
- transformer: ~\(L \times BT(14H + TN)\)
Also see this paper for some activation analysis under 16bit
2. Efficiency
2.1. Architecture Search
Check this blog
2.2. Gradient
Model (Gradient Checkpoint)
- part of the forward memory are wiped out to save memory usage
- those forward weights will be recomputed when necessary during backward
- check the gif here
See here for pytorch's implementation
2.3. Pruning
Model (LOTTERY TICKET HYPOTHESIS) unpruned connection’s value is then reset to its initialization, then retraining
2.4. Distillation
2.5. Ensemble
Model (model soup) averaging the weights of multiple models finetuned with different hyperparameter configurations often improves accuracy and robustness
greedy soups, where models are sequentially added to the soup if they improve accuracy on held-out data, outperforms uniform averaging.
3. Quantization
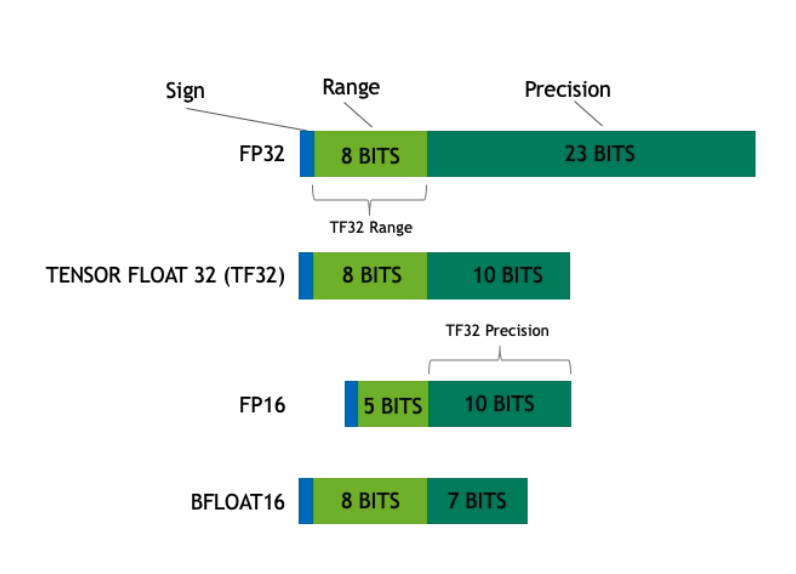
current NVIDIA Tensor Cores seems to support many precisions:
- TF32: TensorFloat32 has 19bits fits within a double word (32 bit), it has the same exponent size as float32. TensorCore simply only drops 13 bits of precision when loading a 32-bit float.
- bfloat16: bfloat16 also has the same exponent size as float32
- FP16
- FP8
- INT8
3.1. Post-training Quantization
From Tensorflow website, Post-training quantization is a conversion technique that can reduce model size while also improving CPU and hardware accelerator latency, with little degradation in model accuracy
- simplest form: convert weight to 8bit precision. At the inference time, convert 8bit back to float point and perform float inference
- dynamic range quantization: activations are quantized to 8 bit and computation are done with 8bit precision
- full integer quantization: everything is quantized to integer. A calibration process is needed to estimate the range of float (min, max). Therefore, a representative dataset is needed.
3.2. Quantization-Aware Training
Pro is achieve higher accuracy, Cons are required training pipline, labeled data and hyperparameter tuning.
3.3. Float16 Quantization
3.3.1. Mixed Precision Training
Tensor Core in GPU supports efficient execution of convolution and matrix multiplicat (AB+C) with float16.
Model (mixed precision) forward/backward are done with FP16, grads are then used to update the FP32 ref weights
see Nvidia's manual for more details
One issue in handling 16-bit is overflowing and underflowing illustrated in the following figure. For example, many activation gradient will become 0 due to the FP16's range.
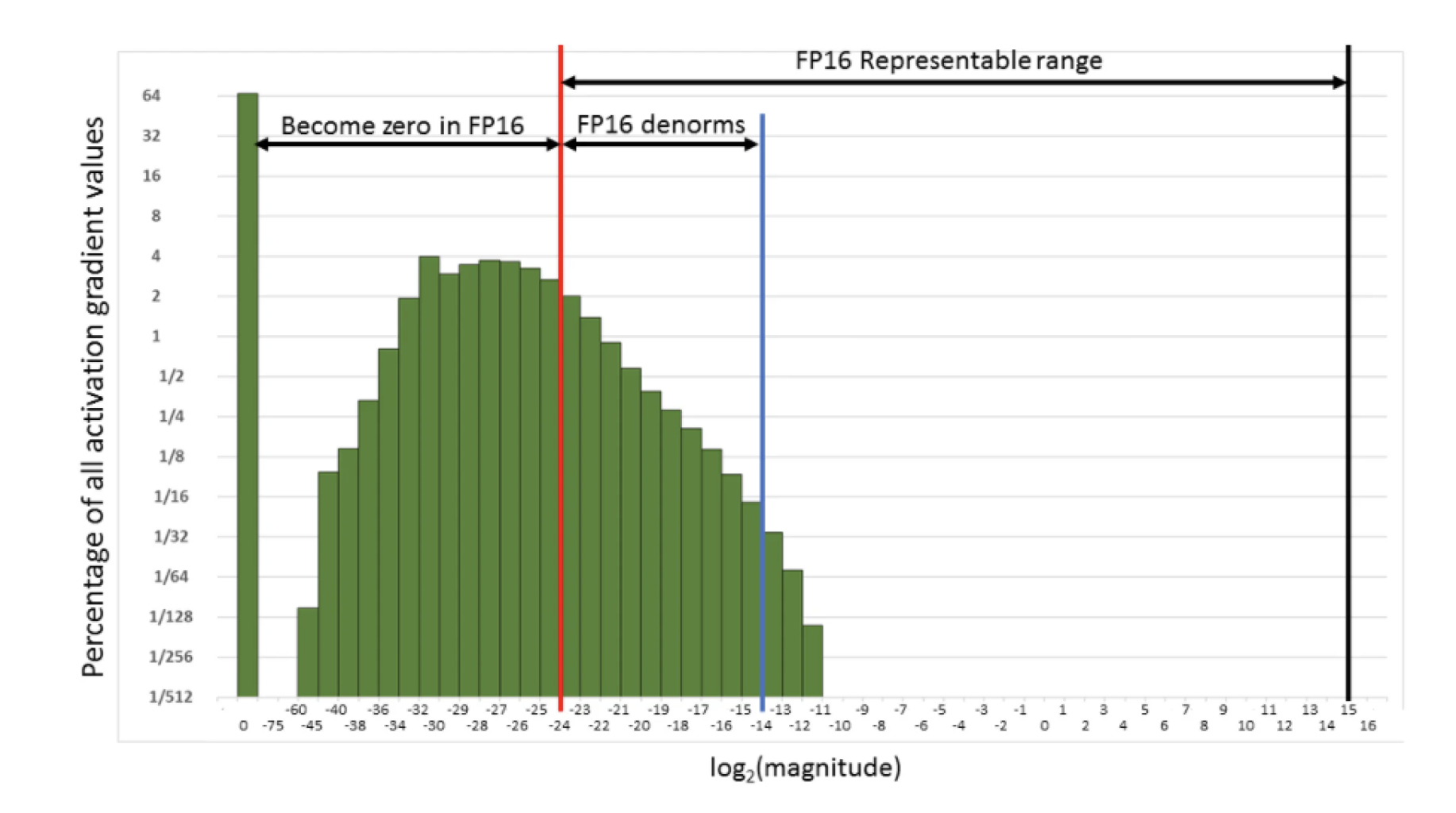
To prevent this issue, a scaling factor should be applied to loss before backprop. This factor can be chosen dynamically.
The overall procedure for training is
Maintain a primary copy of weights in FP32.
For each iteration:
- Make an FP16 copy of the weights.
- Forward propagation (FP16 weights and activations).
- Multiply the resulting loss with the scaling factor S.
- Backward propagation (FP16 weights, activations, and their gradients).
- Multiply the weight gradient with 1/S.
- Complete the weight update (including gradient clipping, etc.).
3.3.2. BF16
Another way is to use bfloat16, which has the same exponent size as float32
3.4. Int8 Quantization
Check this blog