0x512 Compiler
- 1. XLA
- 1.1. Frontend
- 1.2. IR
- 1.3. Backend
- 2. Triton
- 2.1. Frontend
- 2.2. IR
- 2.3. Optimization
- 2.4. Backend
- 3. Reference
Check this repo
1. XLA
XLA is a collection of domain-specific compiler and runtime.
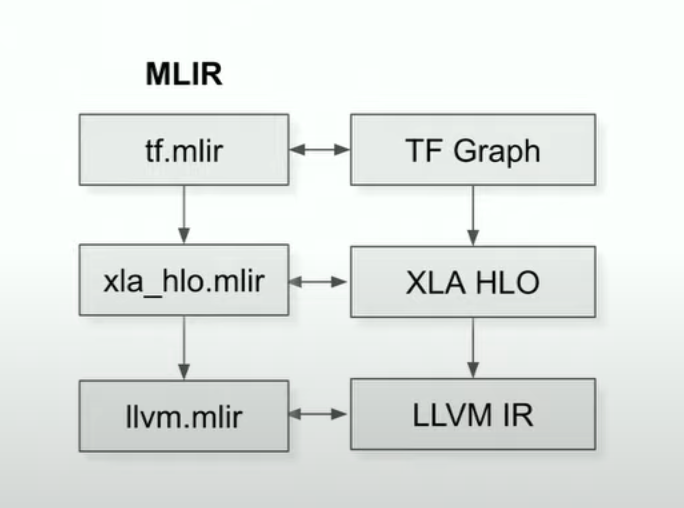
IR is typically represented with MLIR.
MLIR (Multi-Level Intermediate Representation) defines multiple dialects and progressively convert (lowering) towards machine code.
Relevant links
1.1. Frontend
1.1.1. Tensorflow
Tensorflow's execution path is:
There are two bridges for tf2xla:
The traditional bridge implements XlaOpKernel for supported operation in tf.graph. For example, see the softmax XlaOpKernel here. Watch this video
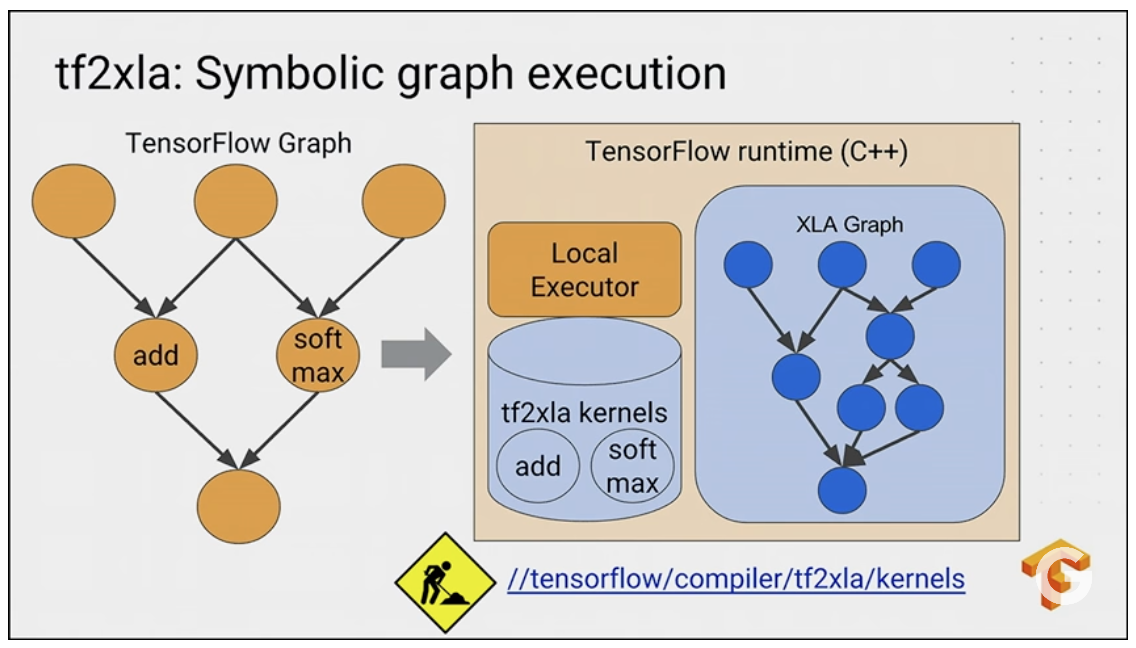
The new bridge takes advantage of mlir translating tf.mlir into hlo.mlir
Examples
@tf.function(jit_compile=True)
def f(x):
return x + 1
f.experimental_get_compiler_ir(tf.random.normal([10, 10]))(stage='hlo')
This will produce the following
HloModule a_inference_f_13__.9
ENTRY %a_inference_f_13__.9 (arg0.1: f32[10,10]) -> f32[10,10] {
%arg0.1 = f32[10,10]{1,0} parameter(0), parameter_replication={false}
%reshape.2 = f32[10,10]{1,0} reshape(f32[10,10]{1,0} %arg0.1)
%constant.3 = f32[] constant(1)
%broadcast.4 = f32[10,10]{1,0} broadcast(f32[] %constant.3)
%add.5 = f32[10,10]{1,0} add(f32[10,10]{1,0} %reshape.2,
f32[10,10]{1,0} %broadcast.4)
%reshape.6 = f32[10,10]{1,0} reshape(f32[10,10]{1,0} %add.5)
%tuple.7 = (f32[10,10]{1,0}) tuple(f32[10,10]{1,0} %reshape.6)
ROOT %get-tuple-element.8 = f32[10,10]{1,0}
get-tuple-element((f32[10,10]{1,0}) %tuple.7), index=0
}
XLA can fuse multiple operations into one operation, therefore improve in both excution speed and memory usage, this can be seen by setting the stage to optimized_hlo
print(f.experimental_get_compiler_ir(tf.random.normal([10, 10]))(stage='optimized_hlo'))
which yields the following, notice that it is shorter by removing some redundent reshape ops
HloModule a_inference_f_87__.9, alias_passthrough_params=true, entry_computation_layout={(f32[10,10]{1,0})->f32[10,10]{1,0}}
%fused_computation (param_0: f32[10,10]) -> f32[10,10] {
%param_0 = f32[10,10]{1,0} parameter(0)
%constant.0 = f32[] constant(1), metadata={op_type="AddV2" op_name="add"}
%broadcast.0 = f32[10,10]{1,0} broadcast(f32[] %constant.0), dimensions={}, metadata={op_type="AddV2" op_name="add"}
ROOT %add.0 = f32[10,10]{1,0} add(f32[10,10]{1,0} %param_0, f32[10,10]{1,0} %broadcast.0), metadata={op_type="AddV2" op_name="add"}
}
ENTRY %a_inference_f_87__.9 (arg0.1: f32[10,10]) -> f32[10,10] {
%arg0.1 = f32[10,10]{1,0} parameter(0), parameter_replication={false}, metadata={op_name="XLA_Args"}
ROOT %fusion = f32[10,10]{1,0} fusion(f32[10,10]{1,0} %arg0.1), kind=kLoop, calls=%fused_computation, metadata={op_type="AddV2" op_name="add"}
}
1.1.2. Jax
Jax's execution path is roughly
Lowered stage traces jaxpr into StableHLO in the MHLO form (mlir-HLO). Notice this is only translation, not optimization.
@jax.jit
def one_plus_one():
a = jnp.ones(1)
b = jnp.ones(1)
return a + b
print(one_plus_one.lower().as_text())
example output is
module @jit_f attributes {mhlo.num_partitions = 1 : i32, mhlo.num_replicas = 1 : i32} {
func.func public @main() -> (tensor<1xf32> {jax.result_info = "", mhlo.layout_mode = "default"}) {
%0 = stablehlo.constant dense<1.000000e+00> : tensor<f32>
%1 = stablehlo.broadcast_in_dim %0, dims = [] : (tensor<f32>) -> tensor<1xf32>
%2 = stablehlo.constant dense<1.000000e+00> : tensor<f32>
%3 = stablehlo.broadcast_in_dim %2, dims = [] : (tensor<f32>) -> tensor<1xf32>
%4 = stablehlo.add %1, %3 : tensor<1xf32>
return %4 : tensor<1xf32>
}
}
Lowered stage can be futher compiled into Compiled stage
Most of the optimization happen at this stage.
compiled = jax.jit(lambda x: x + 2).lower(3).compile()
# execute this
compiled(2)
# Array(4, dtype=int32, weak_type=True)
# some analysis
compiled.cost_analysis()
compiled.memory_analysis()
unfortunately as_text as follows does not show executable binary directly, but the HLO before native binary compilation. Notice that const 1 + 1 is optimized into 2 directly
HloModule jit_f, is_scheduled=true, entry_computation_layout={()->f32[1]{0:T(256)}}, allow_spmd_sharding_propagation_to_output={true}
ENTRY %main.2 () -> f32[1] {
%constant.1 = f32[1]{0:T(256)} constant({2})
ROOT %copy.1 = f32[1]{0:T(256)} copy(f32[1]{0:T(256)} %constant.1)
}
Another similar API is jax.xla_computation achieving similar compile results.
1.1.3. Pytorch
1.2. IR
Confusingly, it seems there are a few IRs and formats, the most commonly used one are StableHLO, MHLO and HLO
1.2.1. StableHLO
StableHLO is a MLIR IR, based on MHLO dialect with additional functionalities:
- forward/backward compatibility
- serialization feature defined here
Note it is mainly for interchange and portability purpose and optimizations/transformations is not heavily done.
StableHLO can be targets from torch-mlir as well
See StableHLO docs for more info
1.2.2. MHLO
MHLO adds dynamism to HLO. It allows dimension of shape to be dynamic (represented with ? in textual IR) or static (with a fixed int)
1.2.3. HLO
HLO is designed to be static, it is XLA compiler's native format based on protobuffer and the top-level input IR to XLA compiler for transformations and optimizations.
It has limited orthogonal well-defined ops (< 100). Semantic of HLO is defined in the XLA semantics page
It can be converted from/to StableHLO
1.2.3.1. HloModule
Its proto is defined as follows:
message HloModuleProto {
string entry_computation_name = 2;
// function infos
repeated HloComputationProto computations = 3;
// sharding infos
xla.OpSharding spmd_output_sharding = 12;
repeated xla.OpSharding spmd_parameters_shardings = 14;
bool use_auto_spmd_partitioning = 16;
// DeviceAssignment object information.
DeviceAssignmentProto device_assignment = 15;
}
message HloComputationProto {
string name = 1;
repeated HloInstructionProto instructions = 2;
}
Layout syntax as the following example:
f[100, 256, 256, 3]{0, 3, 2, 1:T(4, 128)S(3)} where 0,3,2,1 indicates the minor to major order of logical dim. T(4,128) is the tiling spec and S(3) is the memory space annotation (e.g. 3=CMEM). In the case of bf16, there might be a second level of tiling such as T(4,128)(2,1)
Sharding is defined using this xla_data_pb2.OpSharding proto
1.2.3.2. HloComputation
HloComputation, HloInstruction proto are defined as follows
message HloComputationProto {
string name = 1;
repeated HloInstructionProto instructions = 2;
}
message HloInstructionProto {
string name = 1;
string opcode = 2;
xla.ShapeProto shape = 3;
xla.OpMetadata metadata = 7;
// Literal, only present for kConstant.
xla.LiteralProto literal = 8;
// Dimensions present for some operations that require reshaping or
// broadcasting, including Reshape, Reduce, ReduceWindow, and Reverse.
repeated int64 dimensions = 14;
// Represents a unique identifier for each Send/Recv instruction pair or
// optionally for collective instructions (AllReduce, CollectivePermute,
// AllToAll). Non-positive channel_id is equivalent to no channel id.
int64 channel_id = 26;
repeated int64 operand_ids = 36;
repeated int64 control_predecessor_ids = 37;
repeated int64 called_computation_ids = 38;
xla.OpSharding sharding = 40;
}
1.2.3.3. Tools
There are a few tools
xla-translate between mhlo and hl
run_hlo_module can be used to run HLO binary:
run_hlo_module --platform=CUDA --reference_platform=Interpreter computation.hlo
It helps compile->modify->run iteration cycles. where compiled HLO dumps can be obtained from compile().as_text() from jax or XLA_FLAGS in tf.
1.2.3.4. Profilers
Both tensorflow and jax offer API to profile with tensorboard-plugin-profile
1.3. Backend
The backend of XLA produces the target-dependent hardware code based on LLVM. They emit LLVM IR necessary to represent the XLA HLO computation, and then invoke LLVM to emit native code from this LLVM IR.
For example, CPU backend implementation for XLA can be found here
1.3.1. IFRT
IFRT is a high-level api focusing on distributed runtime
1.3.2. PJRT
PJRT is a low-level hardware/framework-independent device interface for BOTH compilers and runtimes. Relevant code is in XLA repo
Its main functionality is to
- compiles StableHLO into PjRtExecutable
- execute PjRtExecutable
See this doc for more details
PJRT can be implemented with either C or C++ (which get converted to C later)
For example,
virtual absl::StatusOr<std::unique_ptr<PjRtLoadedExecutable>> Compile(
const XlaComputation& computation, CompileOptions options) = 0;
1.3.2.1. XLA:CPU
There are two existing implementations of PJRT: stream executor and TFRT.
1.3.2.2. XLA:TPU
LLO instruction roughly corresponds to single instruction in TPU ISA
1.3.2.3. XLA:GPU
Seems to use StreamExecutor as a PJRT client right now (because XLA GPU client instantiation will end up here)
1.3.3. Optimization
Optimization in XLA compiler is implemented as HLO passes (transforming HloModule) for example, see the optimization passes in gpu_compiler.cc
1.3.3.1. Fusion
The major speedup of XLA comes from the fusion process where Operator fusion merges multiple operations into a single unit.
- Before this pass, a node in a computation graph is a primitive tensor operation (e.g., convolution, element-wise add, etc.).
- When producer and consumer nodes are fused, intermediate data is stored in scratchpad memory, without transferring it to/from HBM, thereby reducing data communication.
- After the fusion pass, a node in a computation graph is either a single primitive operation or a fused operation with many primitive operations
1.3.3.2. Tile Selection
1.3.3.3. SPMD Partitioner
1.3.3.4. Layout Assignment
when necessary, insert copy ops to transpose matrix appropriately for downstreaming ops (e.g. matmul)
2. Triton
Unlike XLA targeting compiling against the entire graph, triton seems to focus on writing efficient code for a specific kernel.
It is built on top of the tiling concept
2.1. Frontend
2.2. IR
2.3. Optimization
2.4. Backend
a relevant effort for jax is Pallas, which can write kernel language for TPU/GPU