0x513 Distribution
- 1. Data Parallel (Replication)
- 2. Tensor Parallel (Sharding)
- 3. Pipeline Parallel (Vertical Sharding)
- 4. Sequence Parallel
- 5. Inference
- 6. Implementations
- 7. Reference
1. Data Parallel (Replication)
1.1. Naive Data Parallel
Each setup is replicated across devices, during training
- each device receives a shard of the batch
- each device computes its own loss/gradient using its own data shard
- gradient are synchronized after each step
This works well as long as model can fit into a single device
1.2. Fully-Sharded Data Parallel
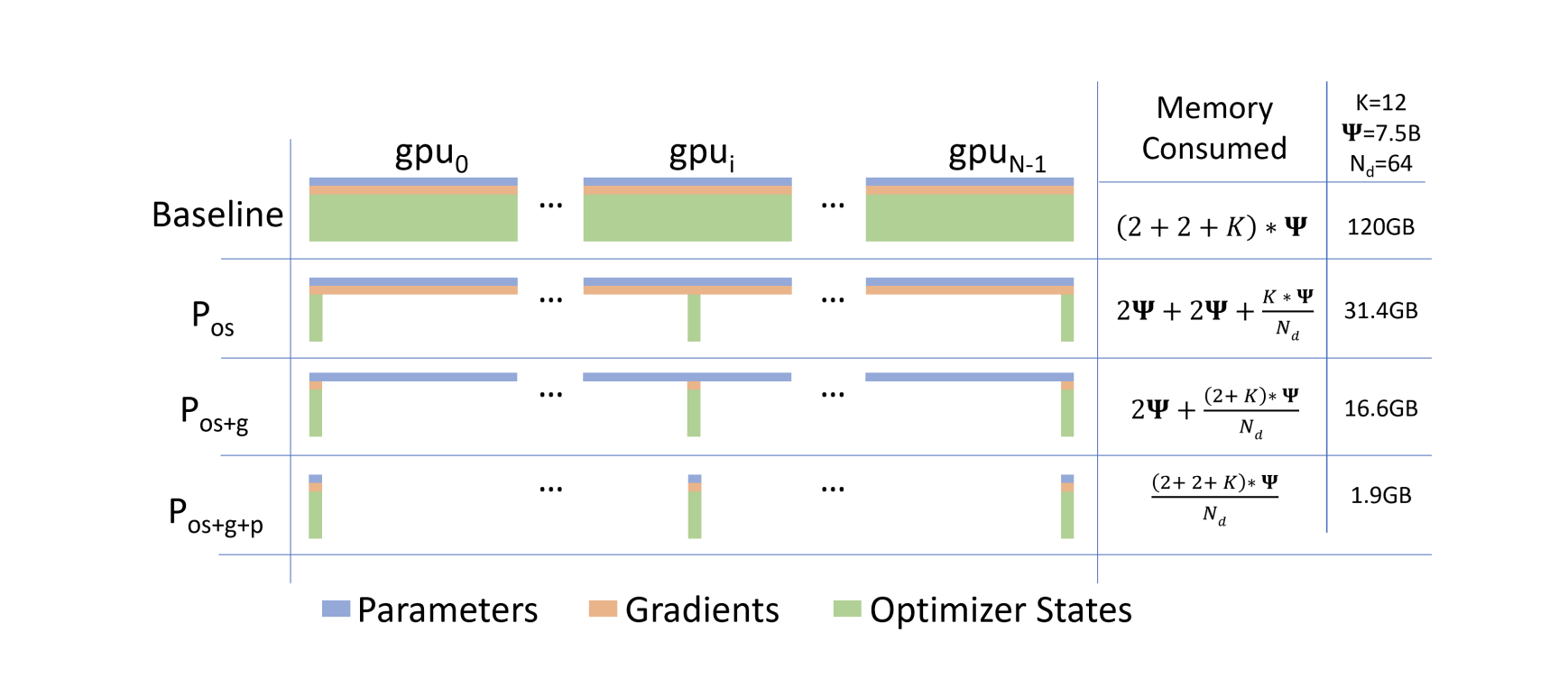
Model (ZeRO) sharding parameter, gradient and optimizer's state across devices
- stage 1: Optimizer State Partitioning
- stage 2: Add Gradient Partitioning
- state 3: Add Parameter Partitioning
According to the paper, a trillion-parameter model with an optimizer like Adam in 16-bit precision requires approximately 16 terabytes (TB) of memory to hold the optimizer states, gradients, and parameters. 16TB divided by 1024 is 16GB, which is well within a reasonable bound for a GPU (e.g., with 32GB of on-device memory)
FSDP pytorch's implementation
2. Tensor Parallel (Sharding)
see this blog for some intuition
2.1. Megatron Sharding
Megatron-LM manually implemented the tensor-sharding by inserting communicating layers into the model.
Sharding layout in Megatron is a very standard layout:
- MLP: sharding at ffw
- Attention: sharding at head
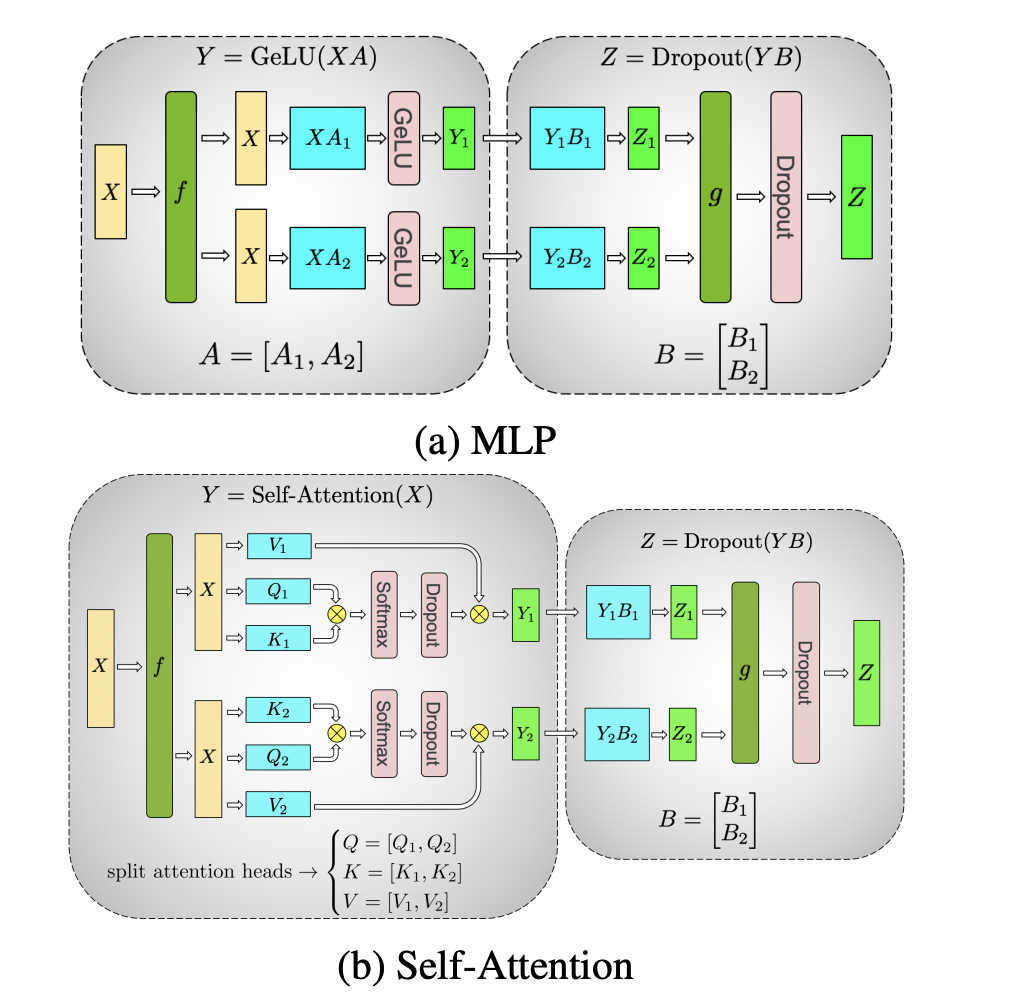
\(f,g\) here are communication layers where:
- f: forward identity, backward allreduce
- g; forward allreduce, backward identity
This approach works well for models up to 20B (fitting A100 x8), and breaks down when models has to be split across multi-hosts due to the slow inter-server links.
The next version combined data-parallel, tensor parallel and pipeline parallel to scale up to 1T params.
2.2. Expert Parallel
Parallelism based on Mixture of Experts
Model (Switch Transformer)
3. Pipeline Parallel (Vertical Sharding)
3.1. Naive Pipeline Parallel
spread layers across multiple devices vertically. For example, place layer 0-3 to device 0 and layer 4-7 to deice 1. DistBelief is one of this example.
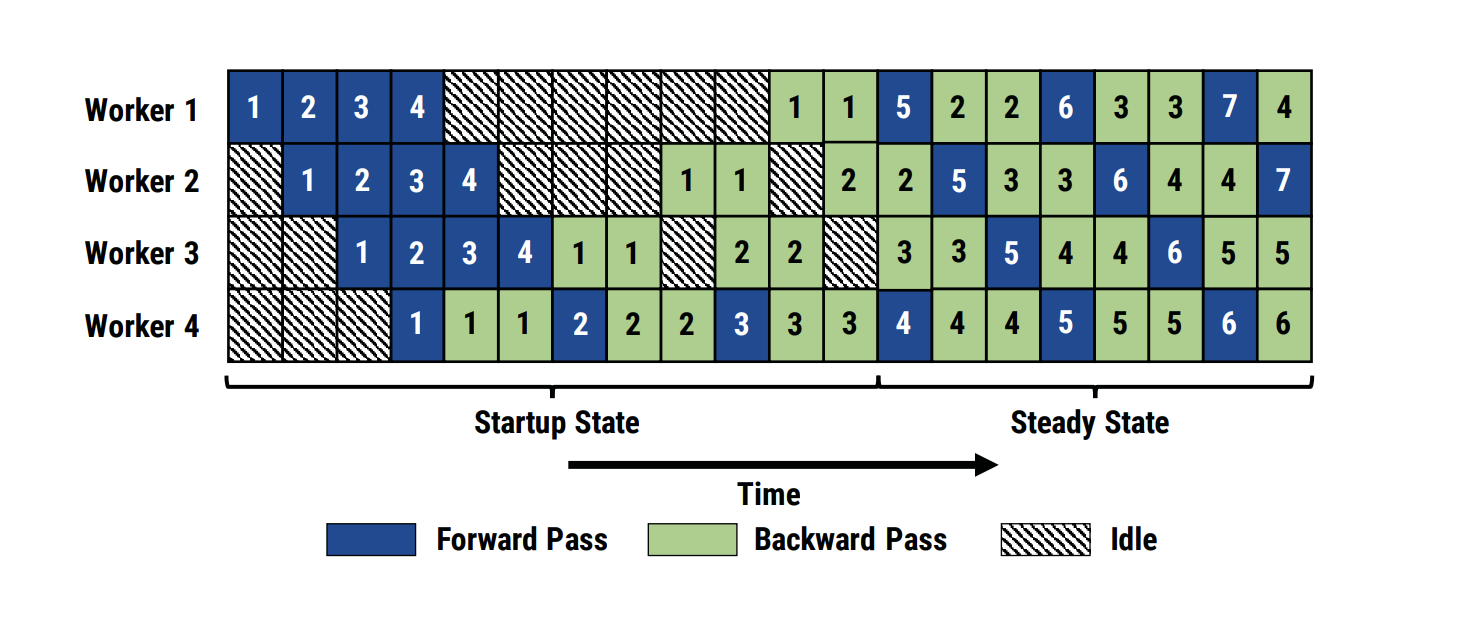
3.2. GPipe Pipeline Parallel
Naive model parallel has local GPU usage, so we come to the pipeline execution
GPipe splits a model into multiple partitions and places each partition on a different device to occupy more memory capacity. And it splits a mini-batch into multiple micro-batches to make the partitions work as parallel as possible.
Checkpointing is also applied to each partition to minimize the overall memory consumption by a model. During forward propagation, only the tensors at the boundaries between partitions are remembered. All other intermediate tensors are volatilized, and recomputed during backpropagation when necessary.
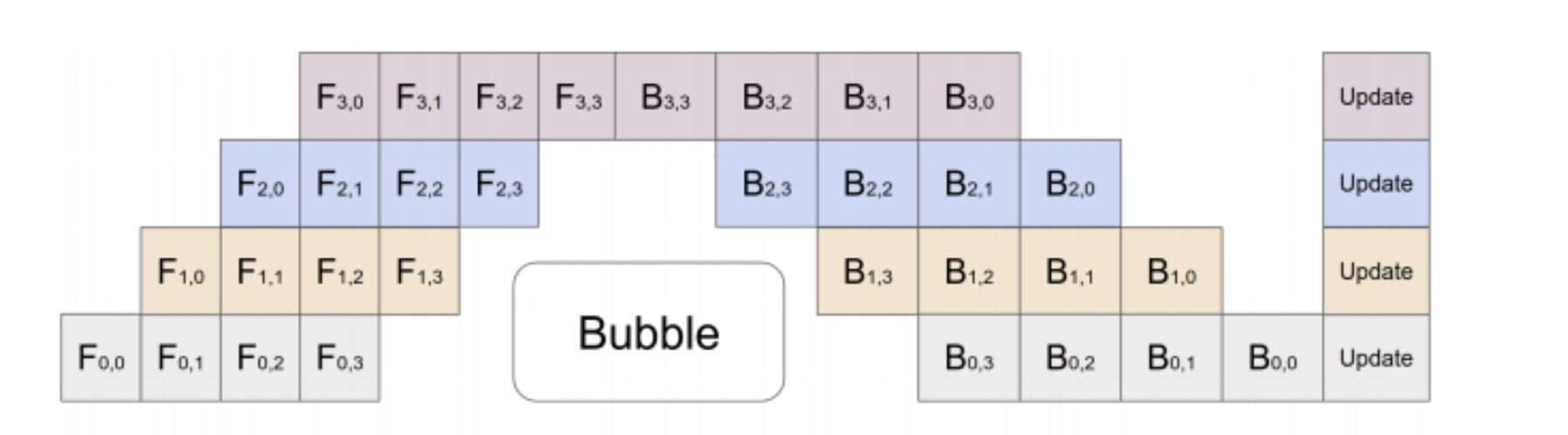
3.3. Advanced Pipelines
4. Sequence Parallel
For example, this work
5. Inference
Model (zero inference)
- deepspeed transformer: GPU only
- heterogeneous inference: GPU + CPU + NVMe
6. Implementations
6.1. Google
6.1.1. XLA Shardings
This section summarizes Google's XLA sharding frameworks (i.e. GShard, GSPMD, Mesh-tensorflow, DTensor...) for both TF and Jax. Check this blog for XLA sharding introduction
GShard provides a few TF annotation APIs (i.e. replicate, split, shard), which requires the user to annotate a few critical tensors in the model with partitioning policies. Those annotations were processed by partitioner in the XLA compiler.
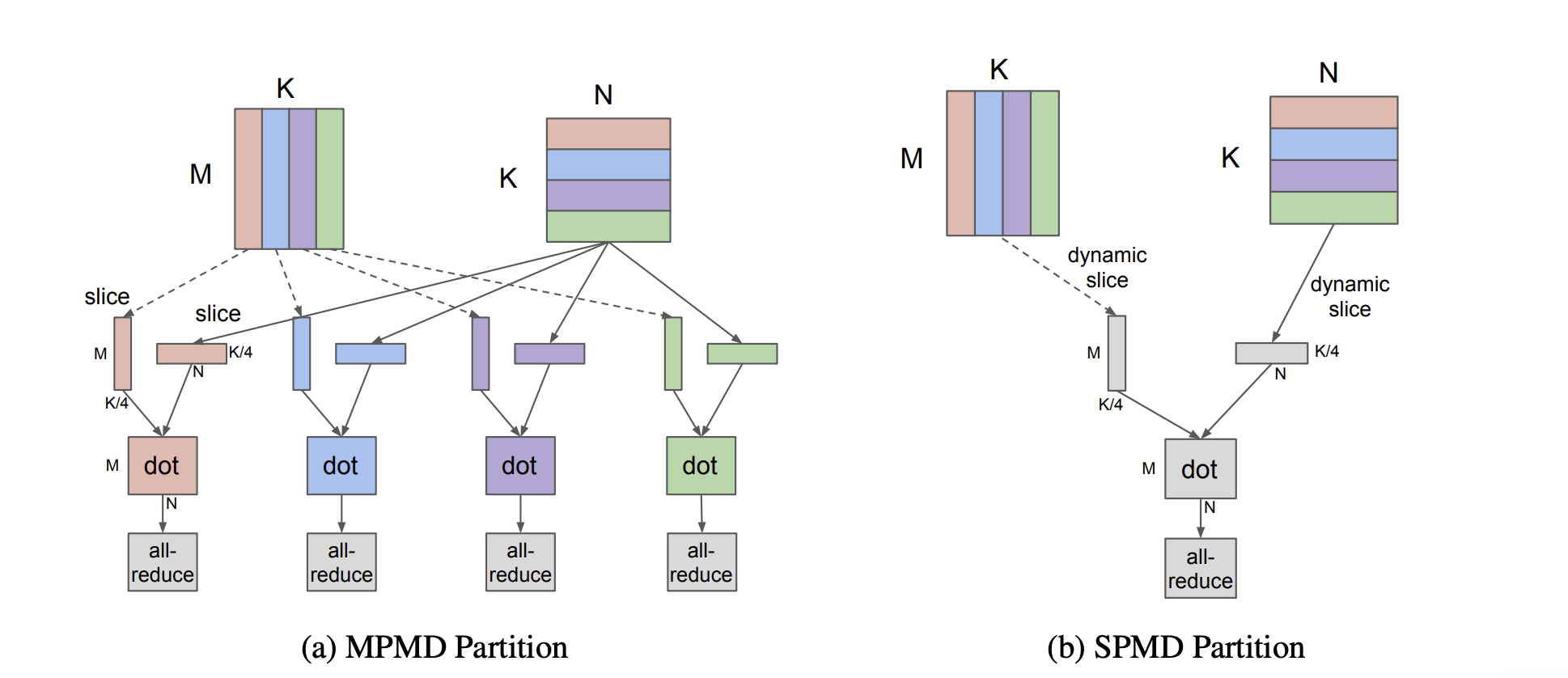
It generates one program (SPMD) for all shards, which is considered better than MPMD as MPMD needs to compile code for each partition, which takes nontrivial time. See the following figure for comparison
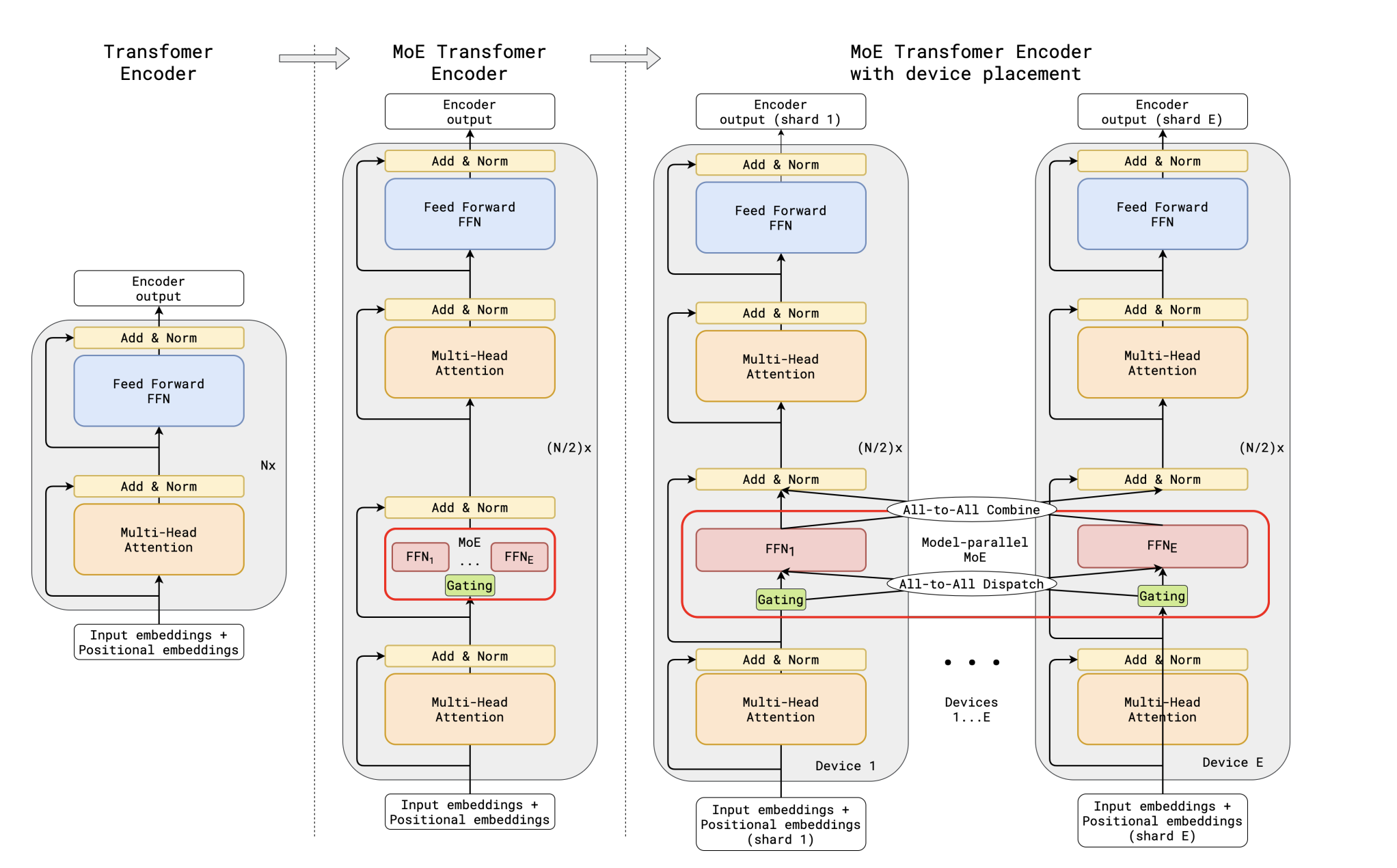
was used to implement the Sparsely-Gated Mixture-of-Experts layers where top 2 experts are activated
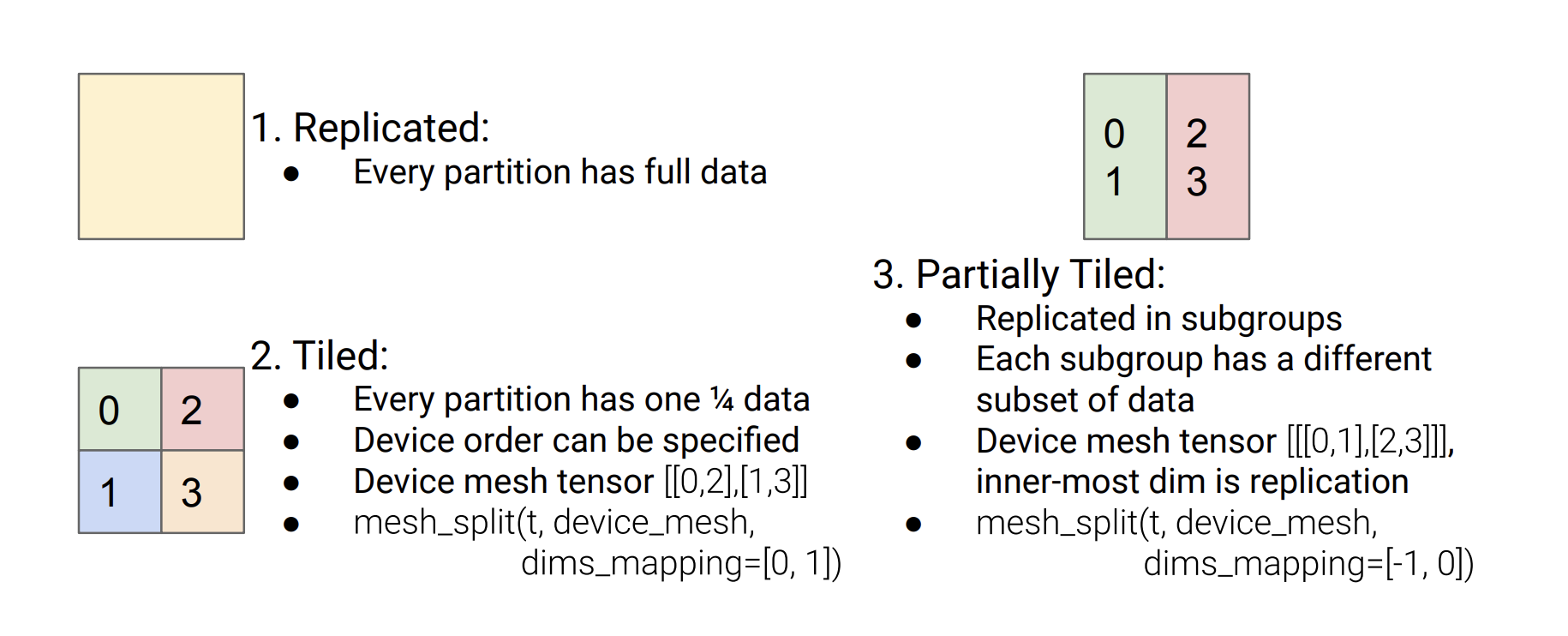
GSPMD is a generalization from the backend of GShard, it introduces a new API of mesh_split(tensor, device_mesh, dims_mapping)
See section 3.5 of GSPMD paper for sharding completions.
6.2. OpenAI
6.3. Nvidia
Megatron series