0x554 Scaling
According to this work: do you need billions of words of pretraining data LM requires only 10M or 100M words to learn syntactic/semantic features, a much larger database (1B, 30B) is required to acquire common sense knowledge
The scaling law paper shows cross-entropy loss scales as a power-law wrt model size, dataset size, computation size:
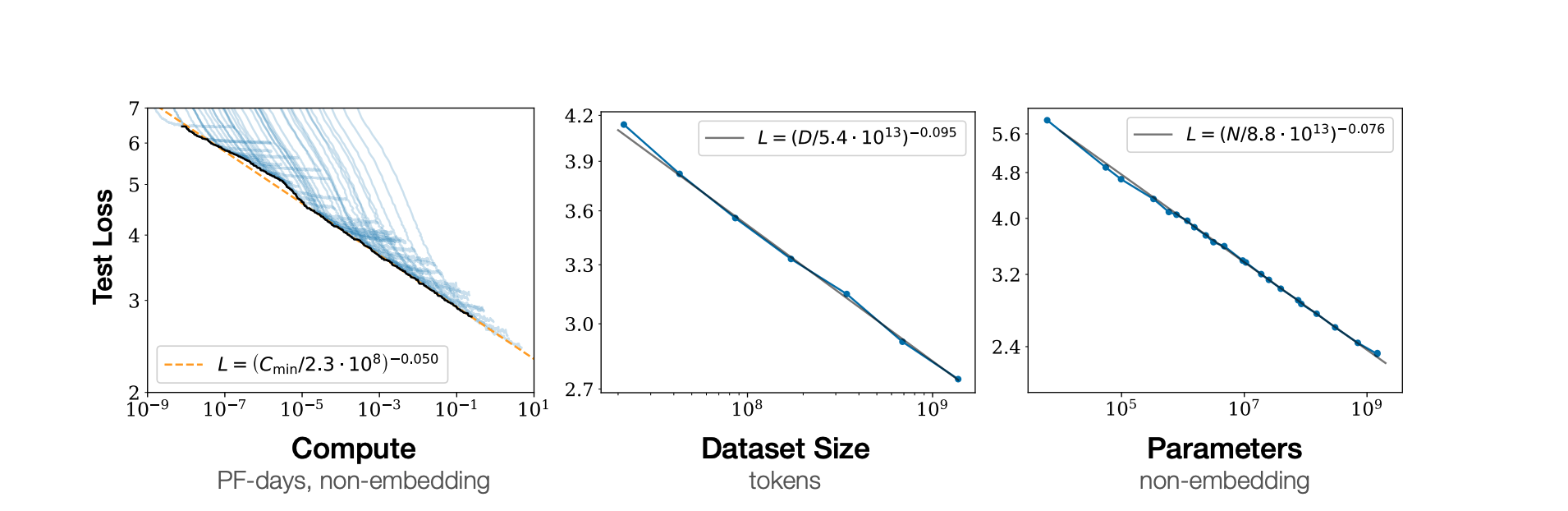
Chichilla paper suggests using training token of 20 times parameters under budget constraint, however, llama 3 training their model with much larger and it continued to improve log-linearly. They train 8B and 70B up to 15T tokens (which should be ~200B token for 8B according to Chinchilla)
Another relevant work is the U-shape scaling, which show that there are a few tasks that has worse performance with larger models, those tasks, however, actually have the U-scaling curve, where the decreased performance with medium model might be explained by the "distractor task"
Check this lecture series