0x572 Task
- 1. Speech Processing
- 2. Speech Synthesis
- 3. Speech Recognition
- 4. Speech Translation
- 5. Spoken Language Understanding
- 6. Reference
1. Speech Processing
1.1. Speech Separation
Deep Cluster (Hershey et al. 2016) achieves speaker separation by building spectrogram embeddings that are discriminative for speaker partitioning with k-means.
where \(V\) is embedding and \(Y\) is label indicator (can be deterministically decided). Embedding is built with minimizing the distance between affinity matrices (equivalent to push embedding from similar labels closer and different labels away)
1.2. Speech Enhancement
1.2.1. Time Domain Models
Model (Demucs)
- encoder-decoder with U-net
- loss is defined over clean signal and enhanced signal
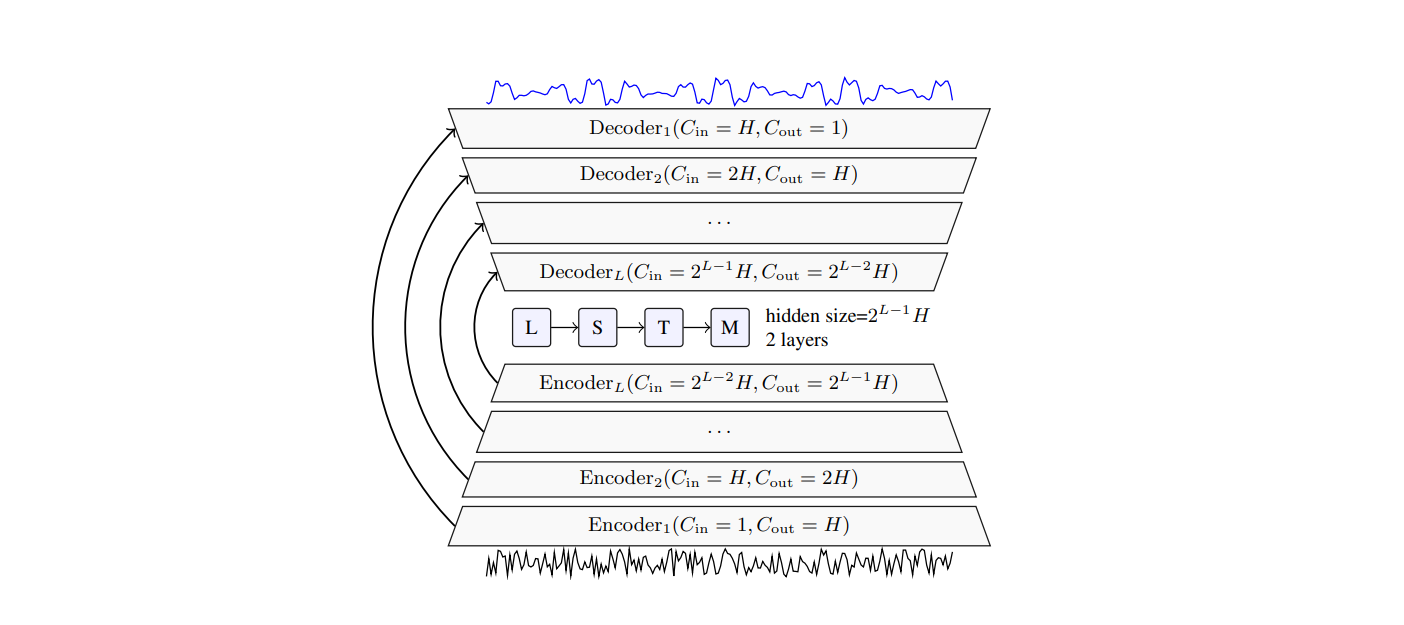
1.2.2. Time-Frequency Domain Models
Model (FullSubNet) minimize complex Ratio Mask and Idea Ratio Mask
1.3. Voice Conversion
Conversion does not need to be speaker conversion, speaking style can also be converted (e.g. emotion, whisper/normal). This topic is similar to image style transfer in CV
1.3.1. Feature Disentangle
1.3.2. Direct Transformation
CycleGAN
StarGAN
Model (Parrotron)
2. Speech Synthesis
2.1. Autoregressive TTS
Model (Tacotron) attention-based s2s model
- input: character
- output: linear spectrogram
- vocoder: Griffin Lim
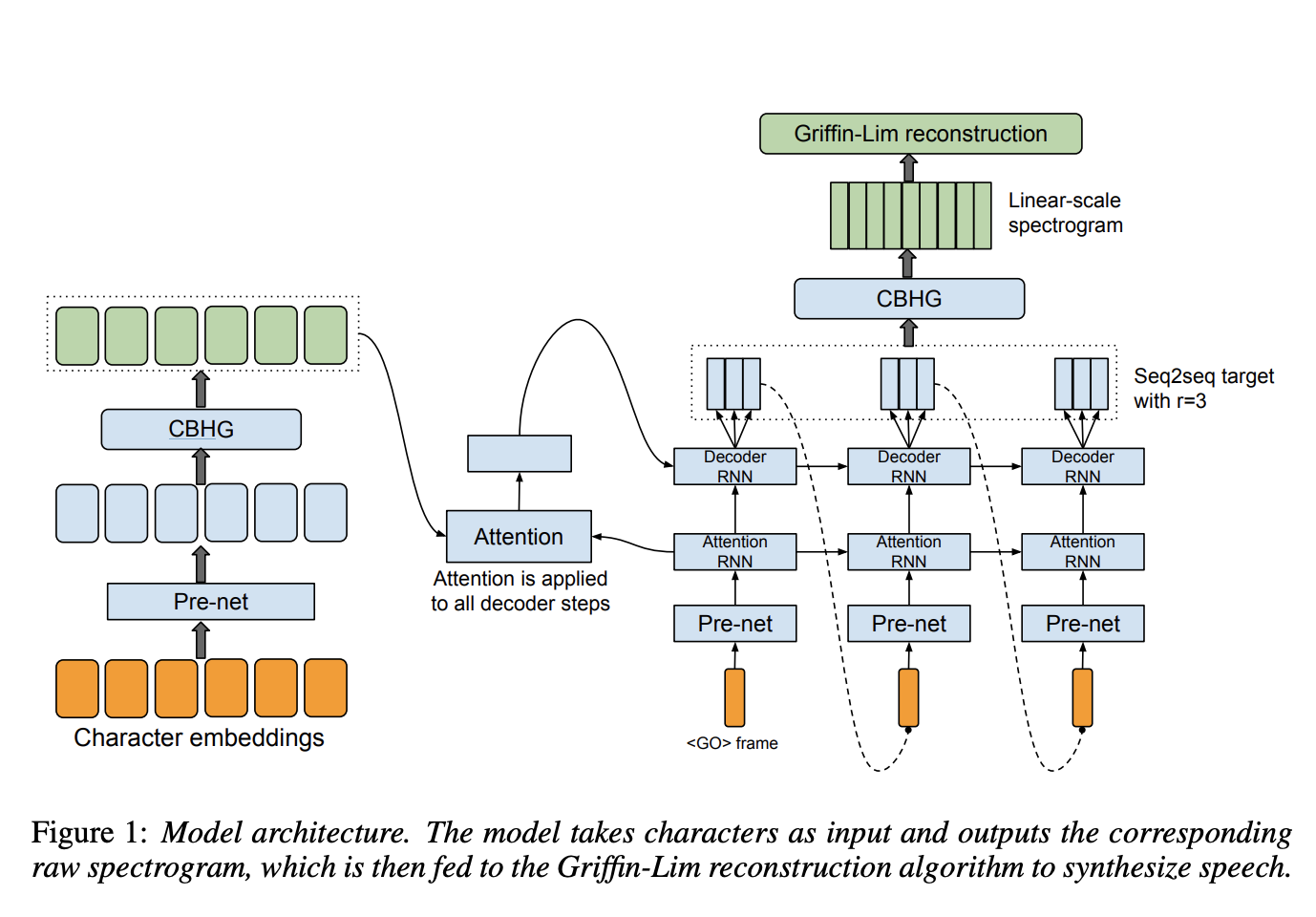
Architecture:
encoder: roughly corresponding to grapheme-to-phoneme model
- prenet: FFN, dropout
- CBHG: conv1d + max-pool along time + highway network + GRU
attention: roughly corresponding to modeling duration
decoder: audio synthesis,
- RNN: each step can generate multiple frames (3,5 frames in v1, only 1 frame in v2)
- prenet: training was done using teacher forcing. but dropout works like the schedule sampling
- postprocessing: non-causal CBHG normalizing autoregressive outputs. loss is applied to both before and after the postprocessing steps
Model (Tacotron 2)
- input: character
- output: melspectrogram
- vocoder: a modified WaveNet
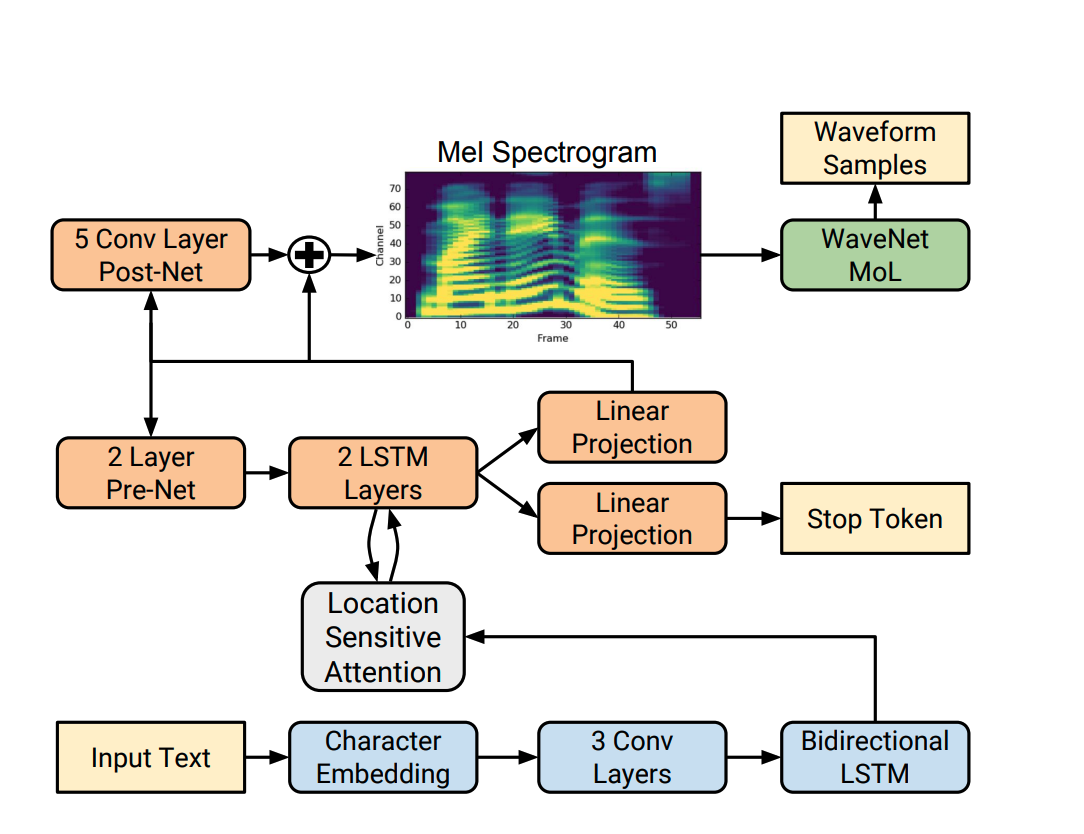
Model (Non-Attentive Tacotron)
it replaces the attention mechanism with the duration predictor
Gaussian Upsampling
- Given \([h_1, ..., h_n]\) and duration values \([d_1, ..., d_n]\) and range parameter \([\sigma_1, ..., \sigma_n]\), the upsampled vector \([u_1, ..., u_t]\) is computed by placing Gaussian distribution to each segment
Unsupervised duration modeling
- extract alignment between input and output using fine-grained VAE similar to this work
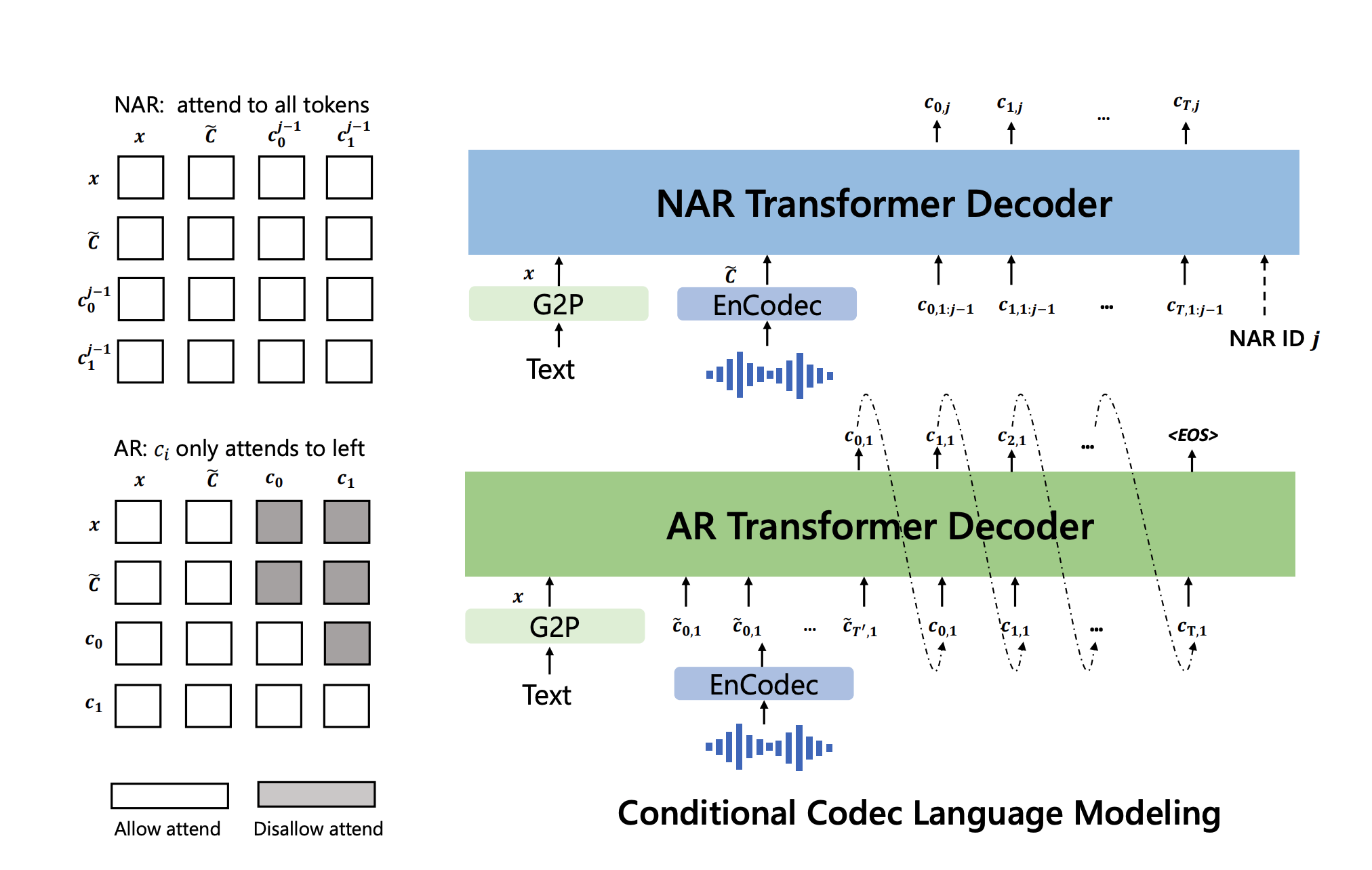
Model (VALL-E)
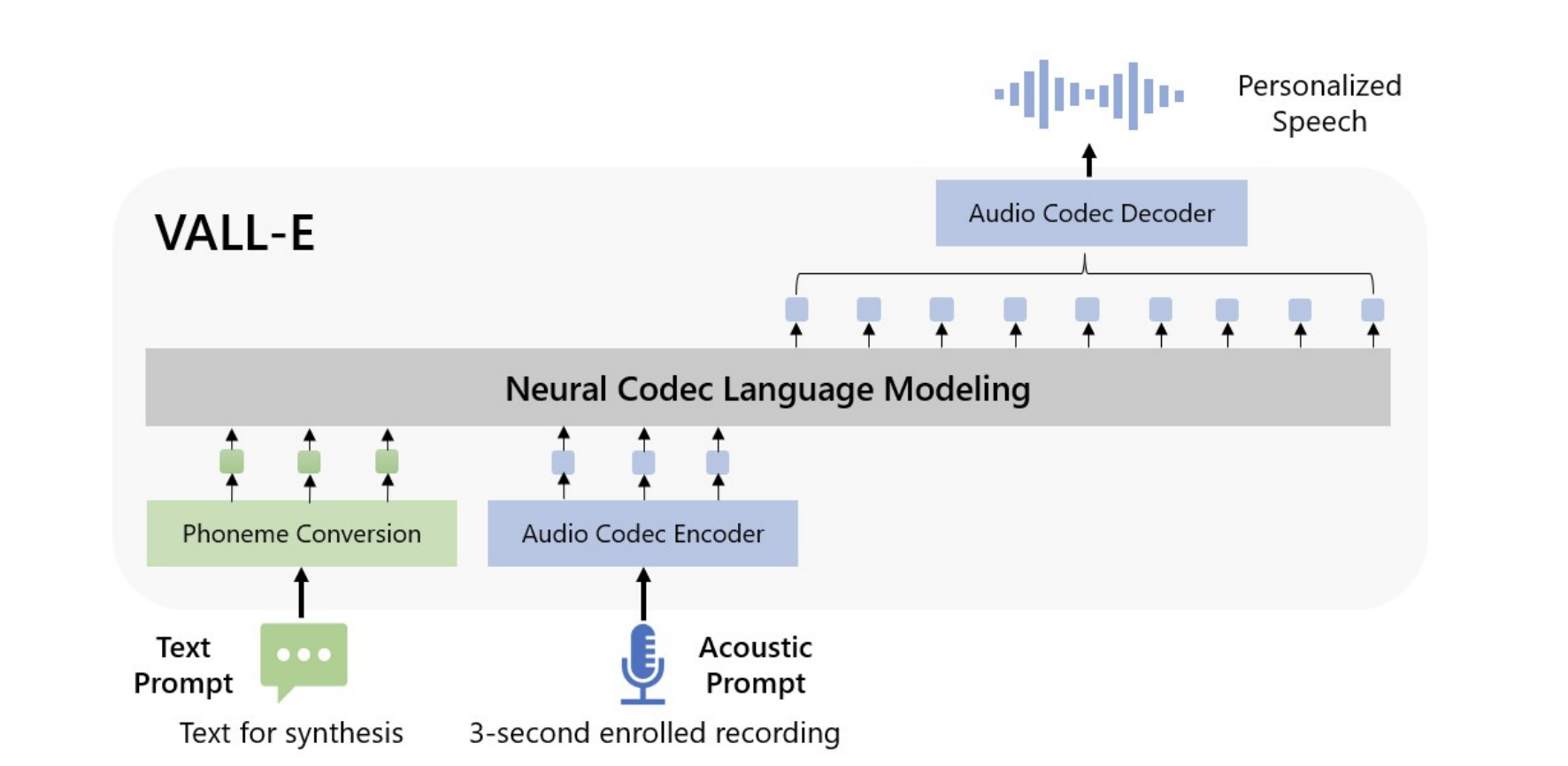
VALL-E uses two models to generate all codecs from EnCodec
- AR model generate codecs from the first quantizer conditioned on the phonemes and codecs prompt (from first quantizer)
- NAR model generate codecs of remaining quantizers (2 to 8 layers) one by one
Note in VALL-E's setting, EnCodec transforms 24kHz waveforms into 75 Hz codecs where there are 8 quantizers and codebook size is 1024. Therefore, each second is represented by 75*8 discrete tokens.
2.2. Non-Autoregressive TTS
Model (Parallel Wavenet) A trained WaveNet model is used as a teacher for a feedforward IAF (inverse autoregressive flow) student
The probability density distillation loss is the KL divergence
Note that the entropy term \(H(P_S)\) is necessary. Otherwise it will collapse to the teacher's mode (mostly silence, see Appendix A.1 in the paper)
Model (FastSpeech) upsample the input sequence by a duration prediction model
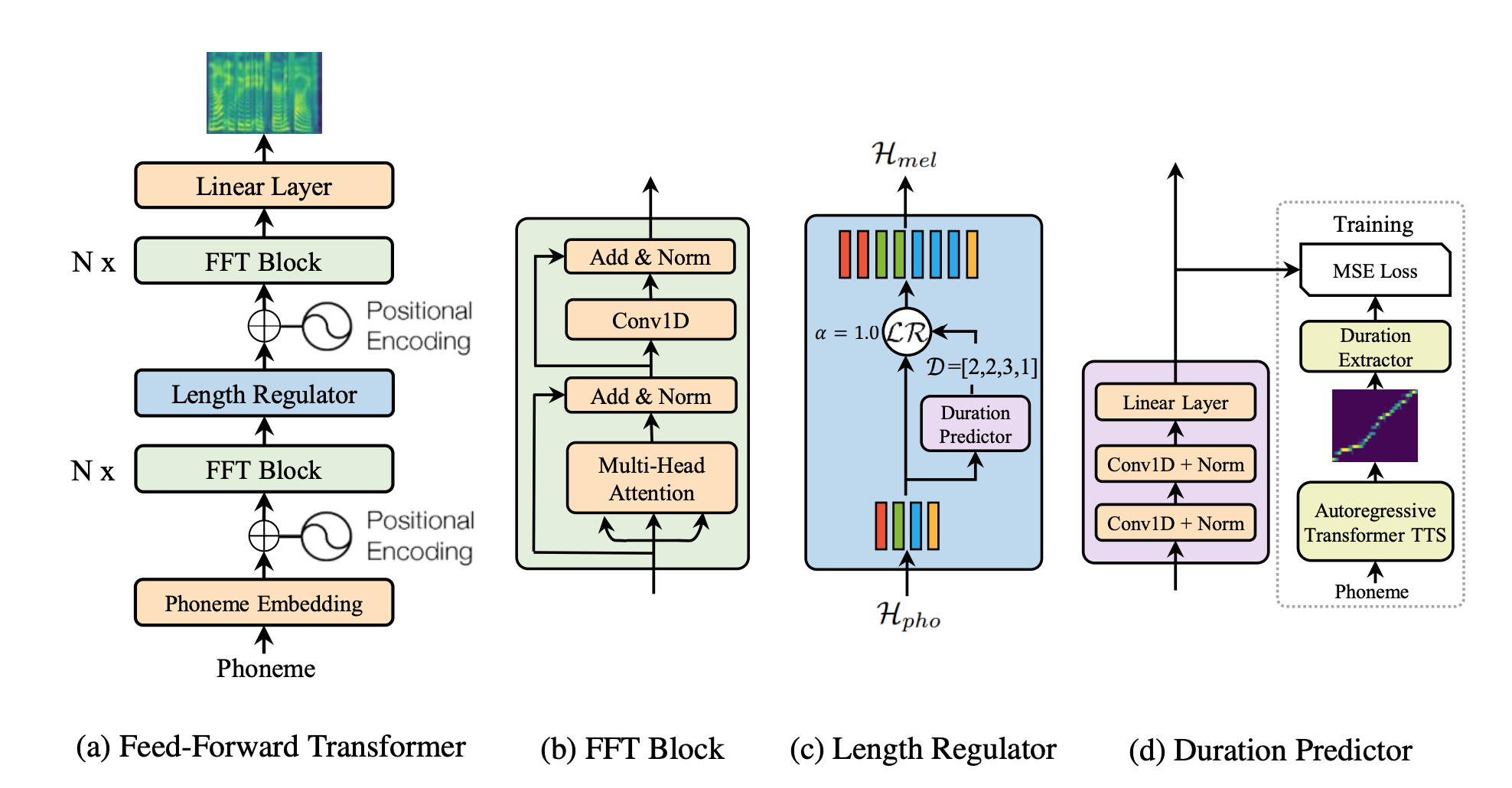
Duration Modeling
-
Duration Predictor:
- 2-layer 1d-conv
- ground truth is extracted from a encoder-decoder transformer TTS's attention alignment. head is choosed using the most diagonal-like attention.
-
Length Regulator:
- expand the hidden state of phoneme sequences by the predicted duration.
- For example hidden states of 4 phonemes are \([h_1, h_2, h_3, h_4]\), its duration are \([2,2,3,1]\), then it expands to \([h_1, h_1, h_2, h_2, h_3, h_3, h_3, h_1]\). A hyperparameter \(\alpha\) can be used to control the voice speed by modifying duration.
Model (FastSpeech 2)
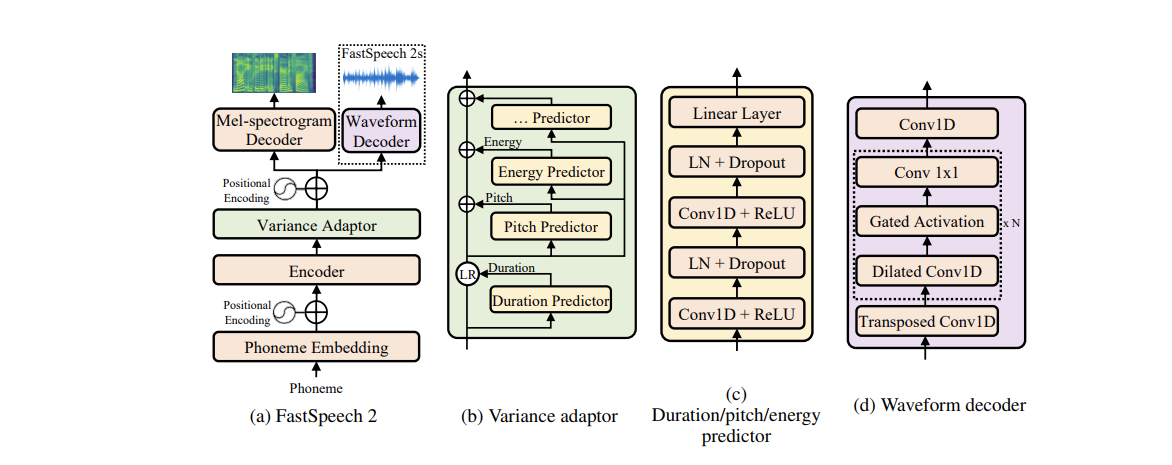
Duration Predictor
- use Montreal force aligner, accurate than the teacher alignment in the original model
Issue (oversmoothing)
2.3. Multispeaker TTS
Model (Deep Voice 2) using speaker embedding, a single neural TTS system can learn hundreds of unique voices from less than half an hour of data per speaker
2.4. Multilingual TTS
Model (remapping input symbol) learn a mapping between source and target linguistic symbols.
Model (byte2speech) map byte to spectrogram, it can adapt to new languages with merely 40s transcribed recording
3. Speech Recognition
4. Speech Translation
There are roughly three types for speech translation systems
- cascaded system: ASR + MT + TTS (F speech -> F text -> E text -> E speech)
- speech-text system: F speech -> E text -> E speech
- speech-speech system: F speech -> E speech
4.1. Speech-to-Text Model
4.2. Speech-to-Speech Model
Speech-to-Speech models do not rely on text generation as a intermediate step, it is a natural approach for languages without a writing system.
4.2.1. Speech to Spectrogram Model
Model (Translatotron 1)
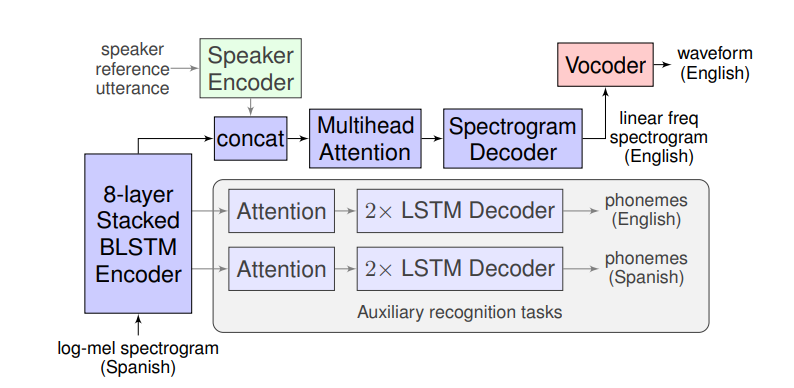
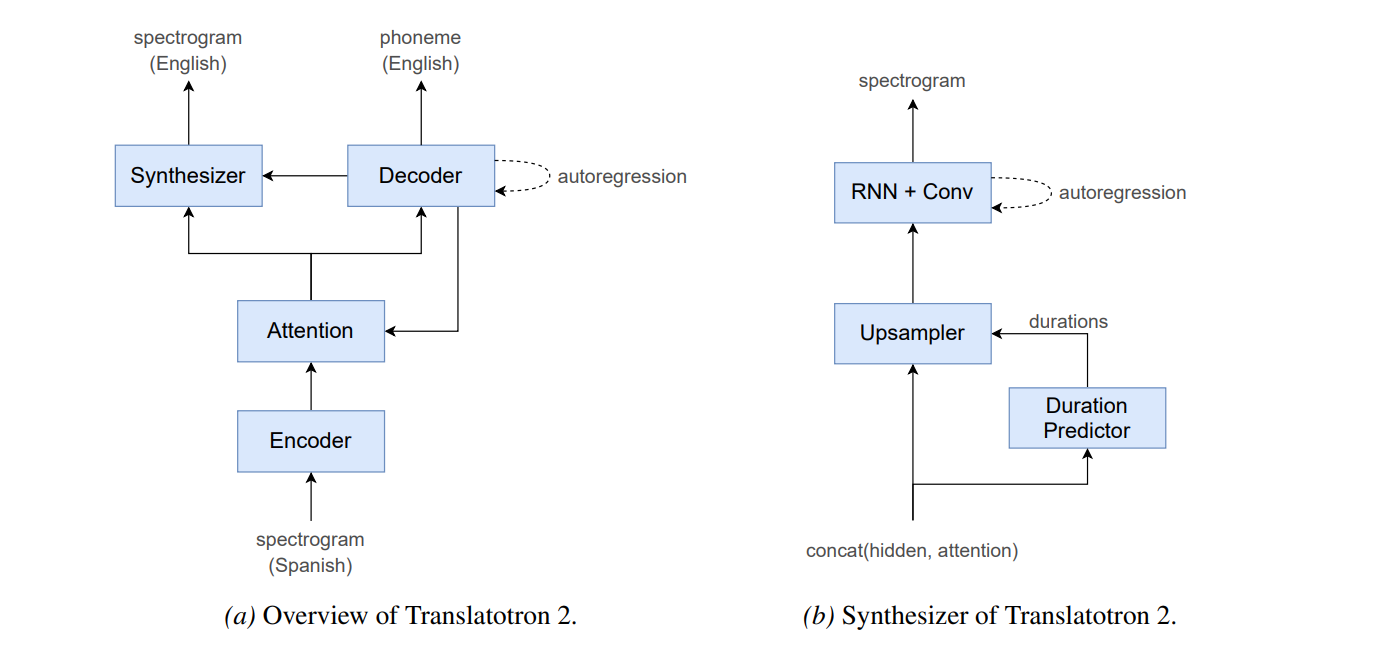
Model (Translatotron 2)
Translatotron 2 improves 1 wrt the following three weakness:
- phoneme alignment is not used by the main task
- long sequence to long spectrogram sequence with attention is difficult to train
The new version has the following component:
- speech encoder: mel-spectrogram to hidden representation using Conformer
- linguistic decoder: encoder output to predict phoneme sequence of translation speech
- acoustic synthesizer: takes the decoder output (before final) and context from attention, it generates spectrogram by non-autoregressive model. Attention is shared with the linguistic decoder
4.2.2. Speech to Discrete-Unit Model
Model (vq-vae)
- train a vq-vae model of the target language
- learn a s2s to map source lang spectrogram to target lang token
- synthesize target lang token into spectrogram and apply Griffin-Lim
Model (xl-vae)
- enhance vq-vae model by adding cross-lingual speech recognition task
- the quantizer aims at reconstructing the target language as well as some other languages' asr task
Model (speech-to-unit translation with ssl)
- Apply self-supervised encoder to the target speech
- Train a speech-to-unit translation model
5. Spoken Language Understanding
5.1. Cascade NLU
5.2. End-to-End SLU
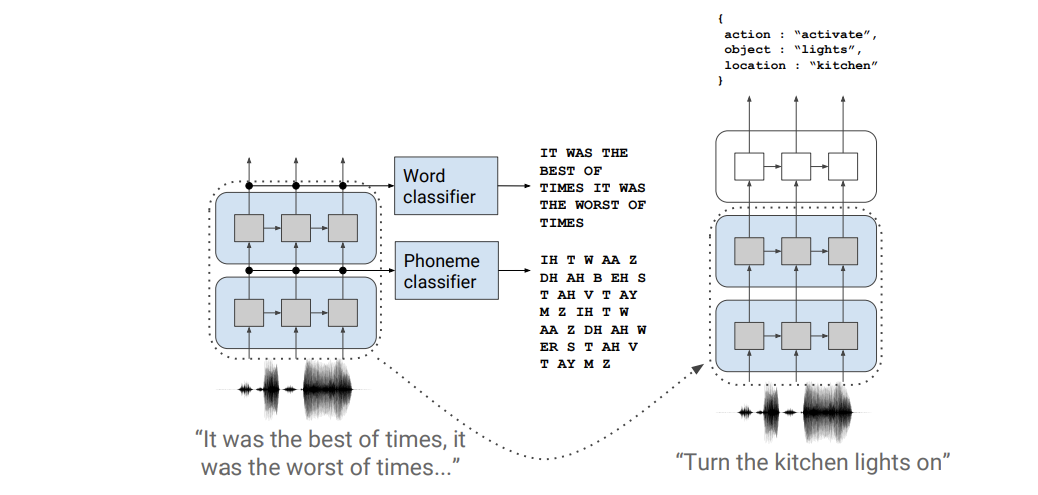
Dataset (Fluent Speech Command)
Each audio clip has three slots: action, object and location. The dataset is trained on the following model
- the lower layers are pretrained using force-aligned phonemes/words
- lower-layer target is discarded and the top layer is trained as a classification task by pooling sequence outputs.
Other relevant papers
6. Reference
[0] original papers. All images are taken from the original papers or blogs
[1] CMU 11751: Speech Recognition and Understanding
[2] Lecture Note on Hybrid HMM/DNN
[3] Hung-yi Lee's lecture: Deep Learning for Human Language Processing