0x560 Representation
1. Image Embedding
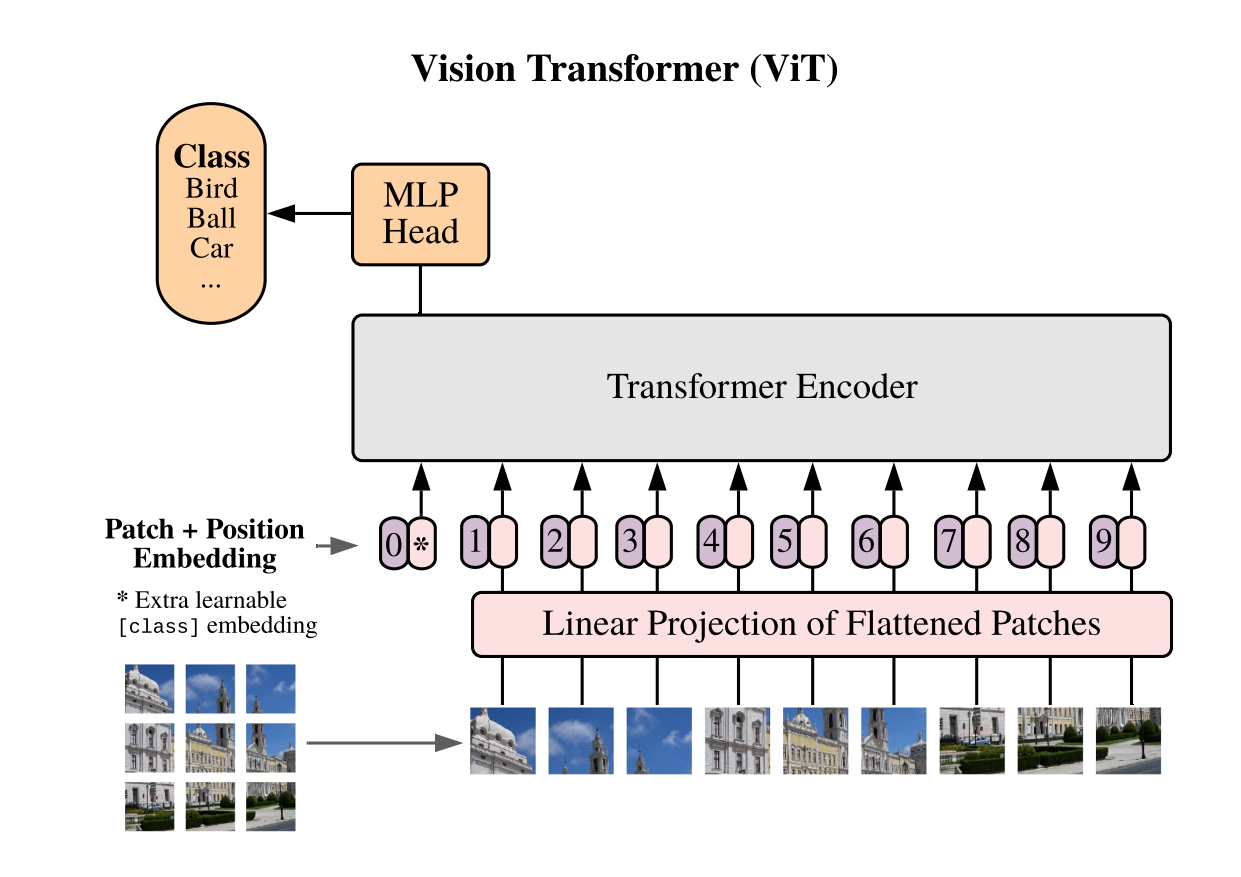
1.1. Vision Transformer
Model (vision transformer, vit) use transformer instead of cnn
- images is splitted into patches, 224x224 images is splitted into 16x16 patches. each patch has 14x14 (196 dim), each patch is like a word-embedding, there are 16x16 words on total.
- a learnable embedding (like the BERT's class token) is prepend before the patch sequence.
- pos embedding (trainable 1d pos embedding) are added
- can be used as a self-supervised training with masked patch prediction.
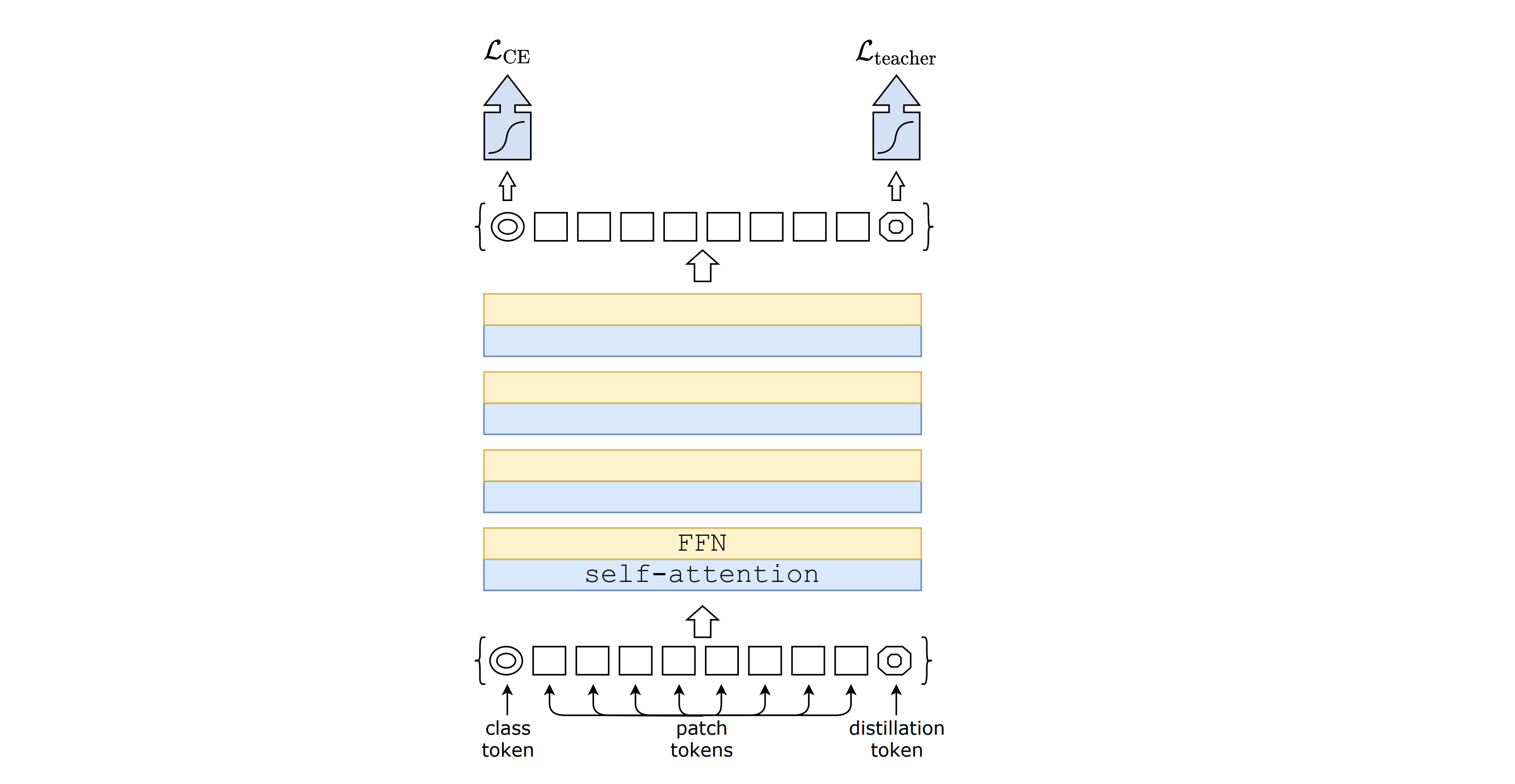
Model (DeiT, data-efficient image transformer) distill information from a teacher ViT model
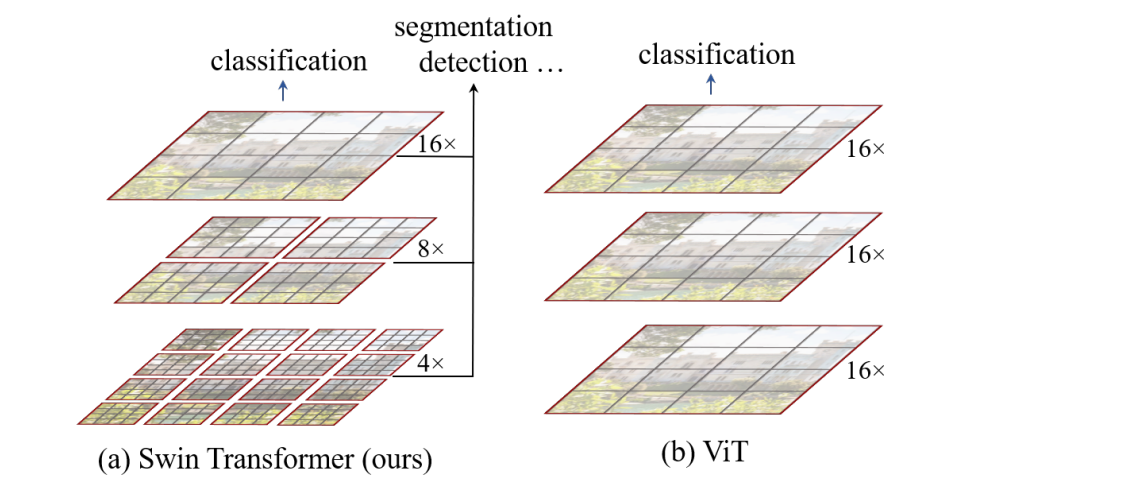
1.1.1. Hierarchical Model
Model (swin transformer)
Swin Transformer block
- attention is limited to a local window
- those window will shifted across layers
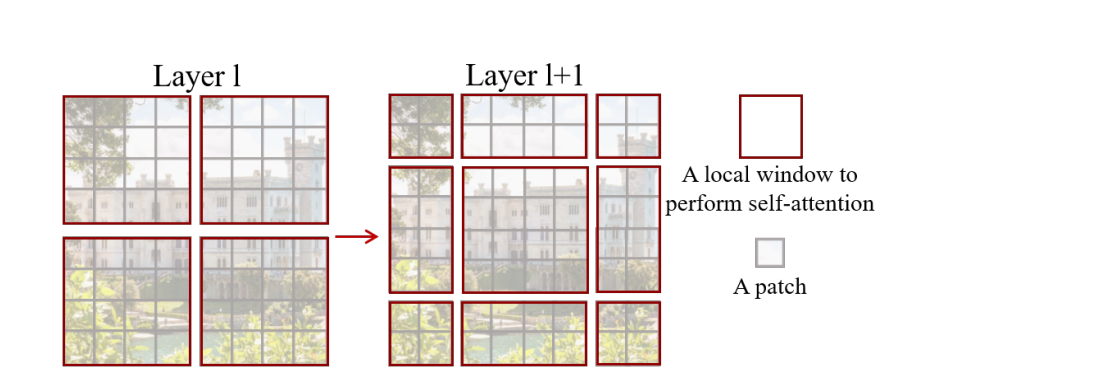
those blocks are forming stages hierarchy in which a layer merging neighbor patches
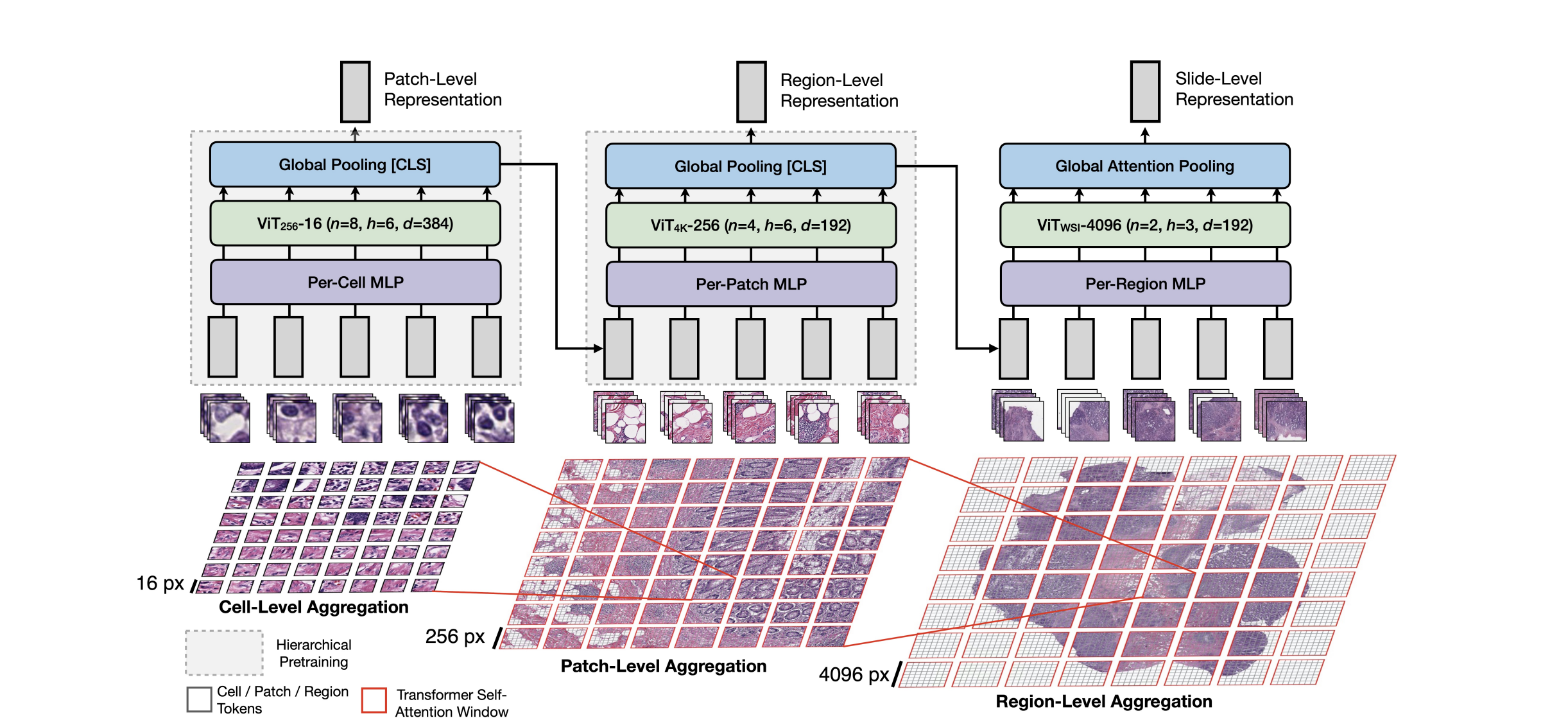
Model (HIPT, Hierarchical Image Pyramid Transformer) High resolution tranformer model using hierarchical model