0x501 Backend
1. Kernel
1.1. Convolution
1.1.1. matrix multiplication
1.1.2. Winograd
Fast Algorithms for Convolutional Neural Networks
1.2. Attention
FlashAttention
reduce communication cost between SRAM and HBM by tiling + rematerilization
2. Execution
2.1. Tensorflow
There are a few runtime for tensorflow
2.1.1. executor
default runtime and served as a reference runtime. It is essentially an interpreter for graphs.
It does some transformation/optimization with Grappler (at the graph level, not IR level) and executed with pre-defined ops kernels.
the execution path is (probably)
tf.graph -> kernels
2.1.2. TFRT
a new runtime which lower graph into BEF format (also defined with MLIR), then executed by BEF executor
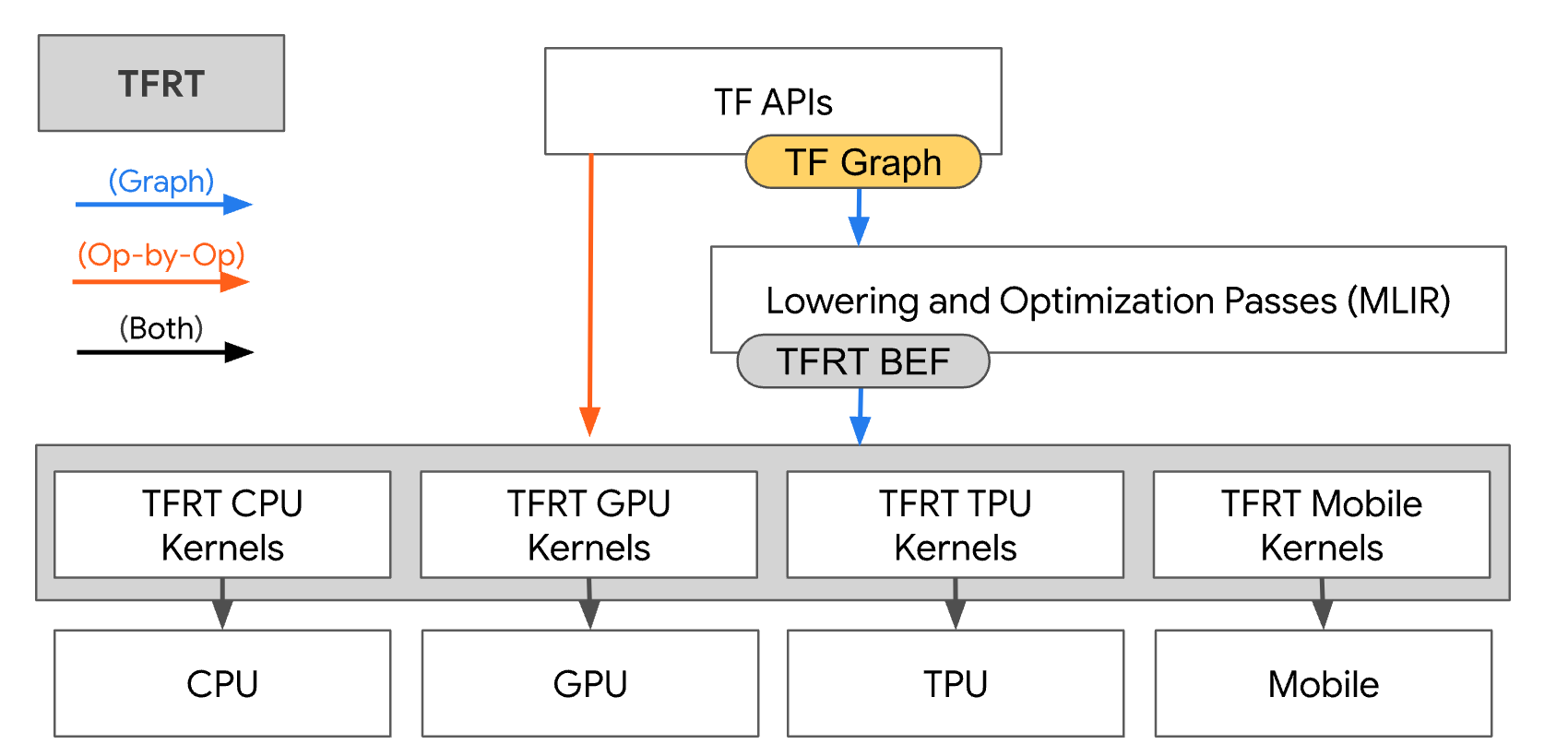
The execution path is
tf.graph -> BEF -> kernels
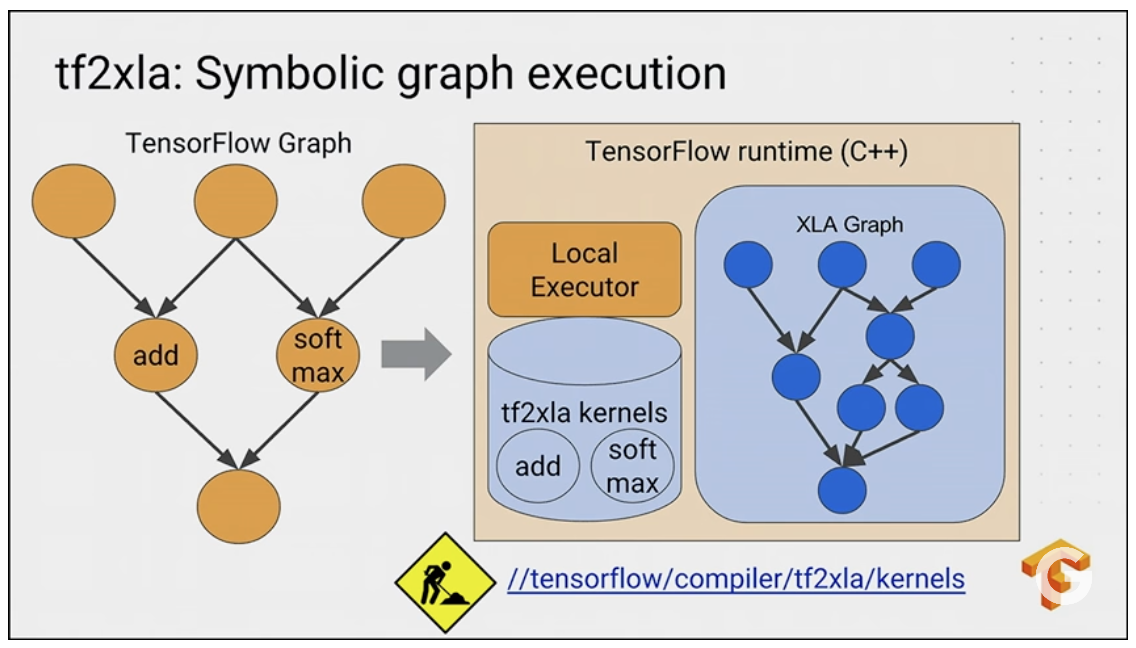
2.1.3. tf2xla (symbolic execution)
The execution path is
tf.graph -> XLA-HLO -> LLVM IR -> kernel
tf2xla implements XlaOpKernel for each operation in tf.graph as the standard kernel in executor, during the execution, this kernel will be a new xla graph, which will be compiled down to the assembly with xla compilation. For example, see the softmax XlaOpKernel here
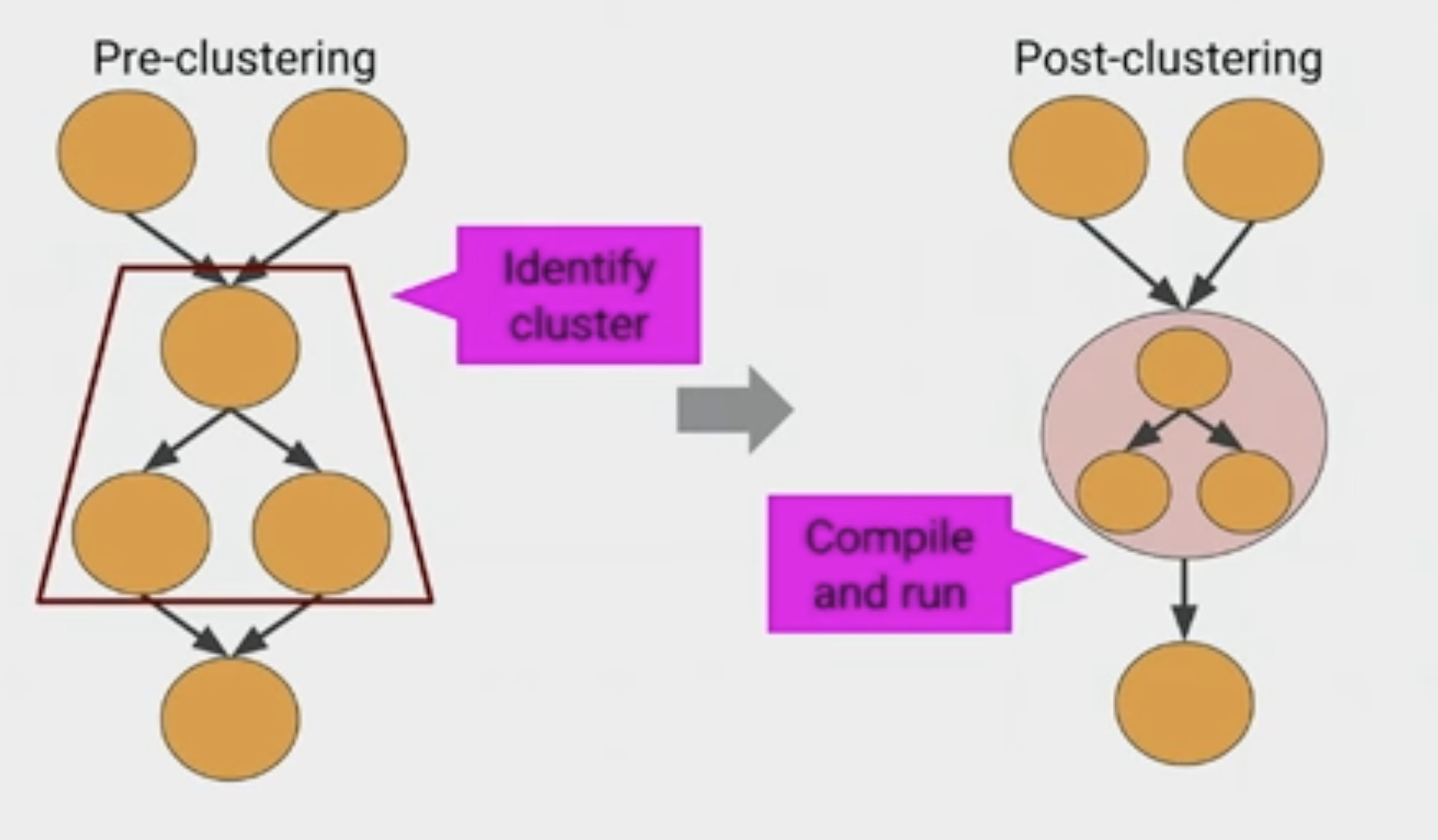
JIT and auto-cluster ops that can be compiled are auto-clustered together. (in tf2, only code inside tf.function will be clustered)
3. Communication
ReduceScatter
3.1. AllReduce
3.1.1. Ring-based Algorithm
implemented with ReduceScatter + AllGather
examples are Horovod and Baidu AllReduce. See Baidu's simple allreduce's implementation using MPI_Irecv and MPI_Send
3.1.2. 2D Ring Algorithm
3.1.3. Double-binary Tree
examples are NCCL implementation. See this blog
4. Compiler
Check this repo
4.1. CUDA
CUDA implementations related to deep learning
4.2. XLA
IR is typically represented with MLIR.
MLIR (Multi-Level Intermediate Representation) defines multiple dialects and progressively convert (lowering) towards machine code.
Relevant links
4.2.1. XLA HLO
HLO has limited orthogonal well-defined ops (< 100), can be lowered from tensorflow graph. Semantic of HLO is defined in the XLA semantics page
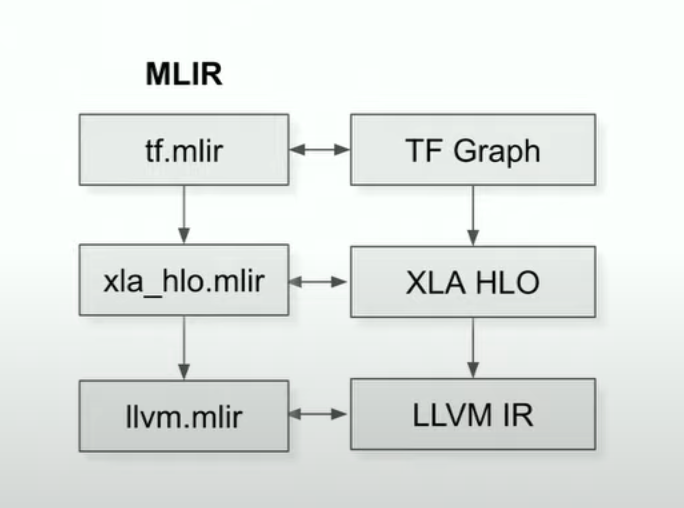
4.2.2. XLA LLO
LLO instruction roughly corresponds to single instruction in TPU ISA
4.2.3. XLA
XLA (Accelerated Linear Algebra) is a domain-specific compiler, this youtube video is a good introduction.
Originally, each operation in the computation graph has a predefined and precompiled kernel that the executor dispatches to, instead XLA compiles the computation graph into a sequence of computation kernels specifically for the model.
Tt can be used as JIT or AOT (ahead of time) compilation.
JIT benefit:
- fast execution (with some compilation overhead)
- this is achieved by binding dim lately to make it static
AOT benefit:
- turn model into executables without runtime.
- this helps to reduce footprint (for example on Mobile)
The major speedup comes from the fusion process:
- without compiler: a op grabs something from memory, do some operation, and write it back to memory, the next op will repeat the same step
- with compiler: if the next op is operating on the same operand, then it directly operating (e.g. within register) without the redundant memory write/read
Another speedup comes from unrolling and vectorizing along some known dimension
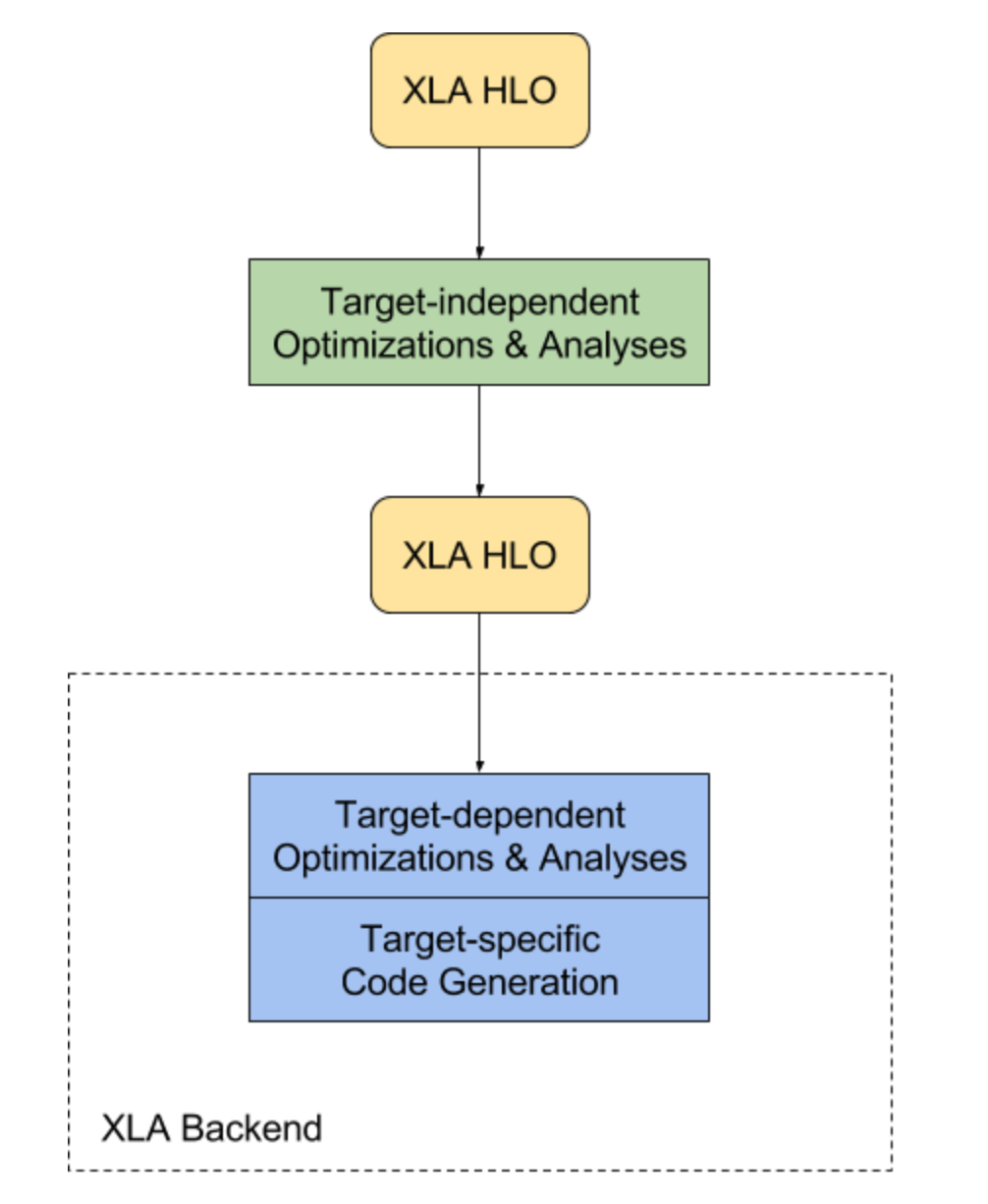
it seems there are several compilation happened inside (something like the LLVM design, which has front/back separation)
- tensorflow API -> XLA HLO: The frontend of XLA produces the HLO (High Level Operation, something like the compiler IR). partitioning also happens here to add comm ops
- XLA HLO -> XLA (optimized) HLO: HLO get optimized
- XLA HLO -> machine code: The backend of XLA produces the target-dependent hardware code. Actually, the backend depends on LLVM. They emit LLVM IR necessary to represent the XLA HLO computation, and then invoke LLVM to emit native code from this LLVM IR. For example, CPU backend implementation for XLA can be found here
A example of the first stage is illustrated as follows:
@tf.function(jit_compile=True)
def f(x):
return x + 1
f.experimental_get_compiler_ir(tf.random.normal([10, 10]))(stage='hlo')
This will produce the following
HloModule a_inference_f_13__.9
ENTRY %a_inference_f_13__.9 (arg0.1: f32[10,10]) -> f32[10,10] {
%arg0.1 = f32[10,10]{1,0} parameter(0), parameter_replication={false}
%reshape.2 = f32[10,10]{1,0} reshape(f32[10,10]{1,0} %arg0.1)
%constant.3 = f32[] constant(1)
%broadcast.4 = f32[10,10]{1,0} broadcast(f32[] %constant.3)
%add.5 = f32[10,10]{1,0} add(f32[10,10]{1,0} %reshape.2,
f32[10,10]{1,0} %broadcast.4)
%reshape.6 = f32[10,10]{1,0} reshape(f32[10,10]{1,0} %add.5)
%tuple.7 = (f32[10,10]{1,0}) tuple(f32[10,10]{1,0} %reshape.6)
ROOT %get-tuple-element.8 = f32[10,10]{1,0}
get-tuple-element((f32[10,10]{1,0}) %tuple.7), index=0
}
XLA can fuse multiple operations into one operation, therefore improve in both excution speed and memory usage, this can be seen by setting the stage to optimized_hlo
print(f.experimental_get_compiler_ir(tf.random.normal([10, 10]))(stage='optimized_hlo'))
which yields the following, notice that it is shorter by removing some redundent reshape ops
HloModule a_inference_f_87__.9, alias_passthrough_params=true, entry_computation_layout={(f32[10,10]{1,0})->f32[10,10]{1,0}}
%fused_computation (param_0: f32[10,10]) -> f32[10,10] {
%param_0 = f32[10,10]{1,0} parameter(0)
%constant.0 = f32[] constant(1), metadata={op_type="AddV2" op_name="add"}
%broadcast.0 = f32[10,10]{1,0} broadcast(f32[] %constant.0), dimensions={}, metadata={op_type="AddV2" op_name="add"}
ROOT %add.0 = f32[10,10]{1,0} add(f32[10,10]{1,0} %param_0, f32[10,10]{1,0} %broadcast.0), metadata={op_type="AddV2" op_name="add"}
}
ENTRY %a_inference_f_87__.9 (arg0.1: f32[10,10]) -> f32[10,10] {
%arg0.1 = f32[10,10]{1,0} parameter(0), parameter_replication={false}, metadata={op_name="XLA_Args"}
ROOT %fusion = f32[10,10]{1,0} fusion(f32[10,10]{1,0} %arg0.1), kind=kLoop, calls=%fused_computation, metadata={op_type="AddV2" op_name="add"}
}
4.3. Numba
check numba docs
4.4. Triton
unlike XLA targeting compiling against the entire graph, triton seems to focus on writing efficient code for a specific kernel.
4.5. Pallas
jax version of triton, writing kernel language for TPU/GPU