0x542 Adaptation
1. In-Context Learning
1.1. Prompting
Survey (Prompt Methods)
pretrain -> prompt -> predict
It has the following steps:
prompt addition: given an input text \(x\), we apply a template to it
answer search: then we search the text \(z'\) which maximizes the pretrained LM score
answer mapping: the highest scoring asnswer \(\hat{z}\) is mapped to the highest scoring output \(\hat{y}\)
This survey has a table of many good examples
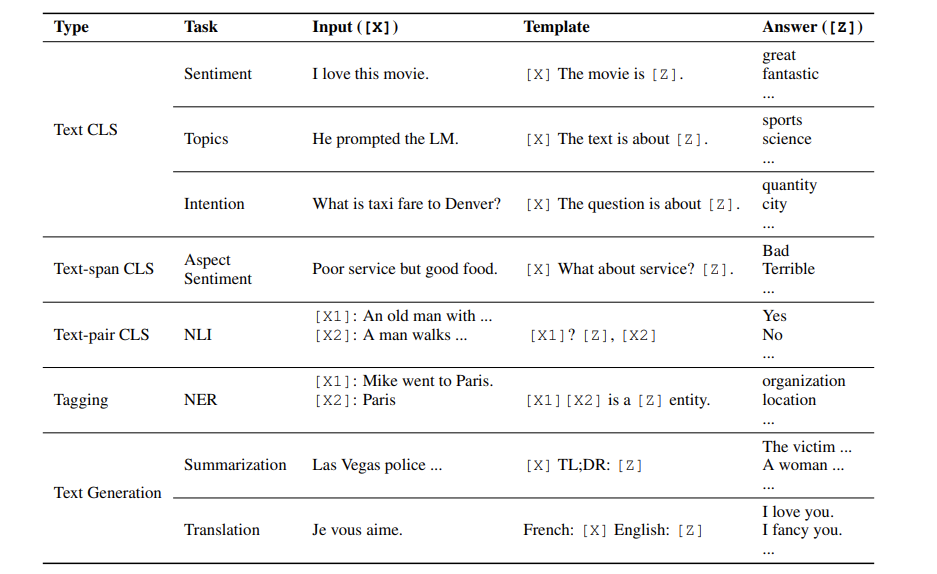
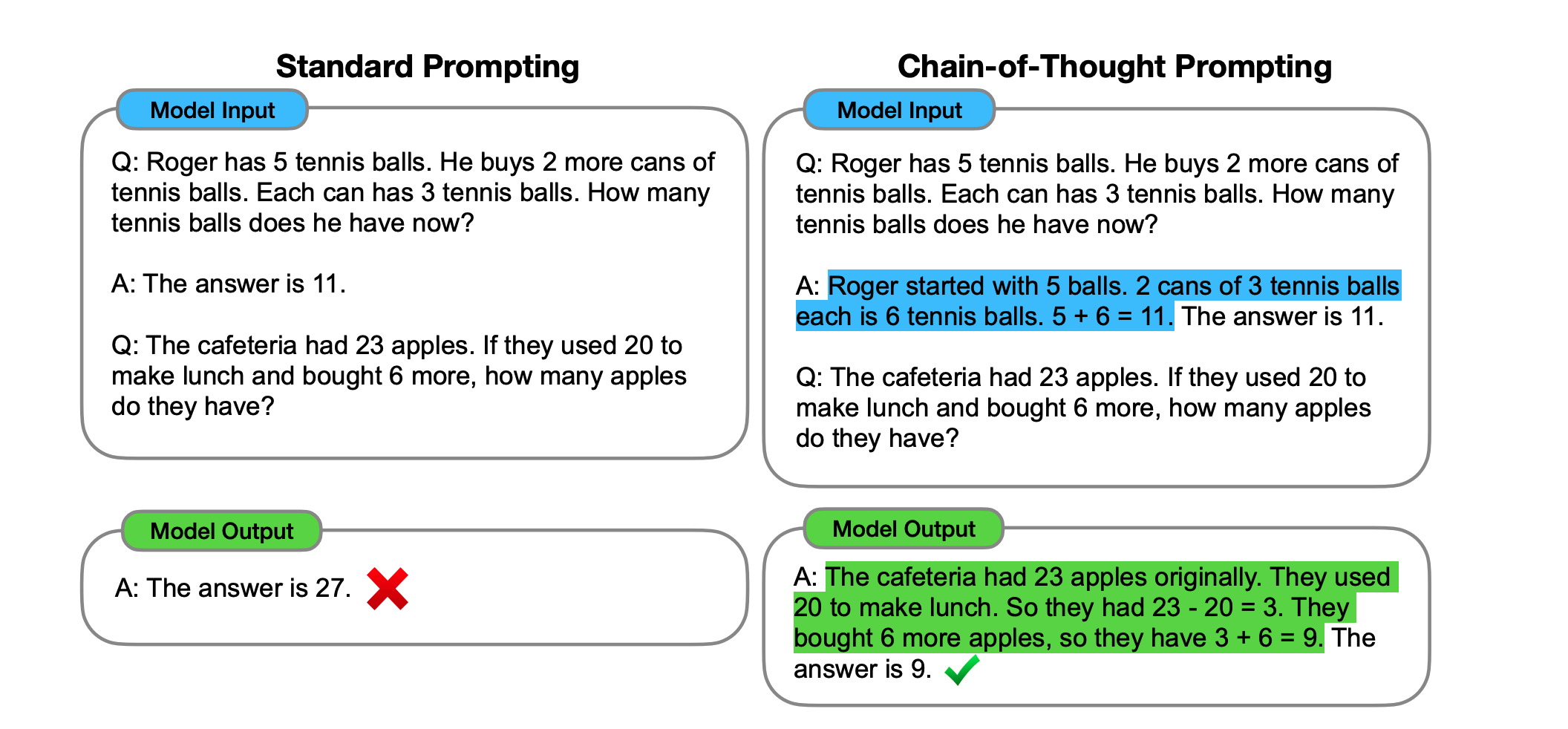
Model (chain of thought) prompt to show how to reasoning:
1.2. RAG
2. Parameter Efficient Fine-tuning
3. Fine-tuning
3.1. Supervised Tuning
Model (GPT) fine-tune the finaly activation pretrained model with the labeled dataset \((x,y)\)
The objective is
The final objective is to combine language model \(L_1\) as an auxilary objective as well (to help convergence and generalization)
To transform any other tasks into the classification task, it apples input transformation as follows:
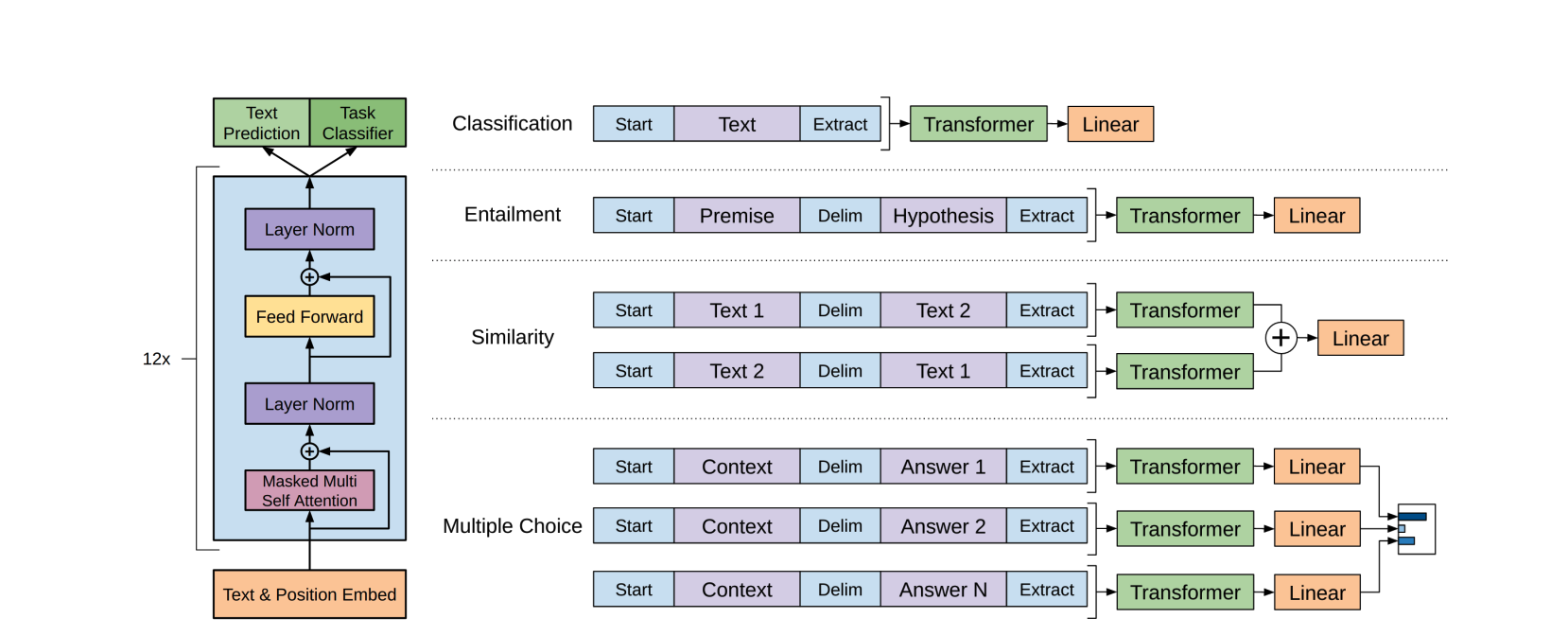
Model (BERT) the downstream task formulation is as follows:
-
sentence -> sentence class: connect the CLS token's embedding with a linear classifier to predict. BERT can be fine-tuned, linear-classifier is trained from scratch
-
sentence -> per word class: connect every word's embedding with a classifier to train.
-
two sentencs -> single class: connect two sentences with SEP token and use the CLI to predict. (e.g. NLI task)
-
sentence -> sentence extraction: If extraction-based QA, suppose document \(D={d_1, d_2, ..., d_N}\) and query \(Q= {q_1, q_2,...,q_M}\), then train a model to use \(D,Q\) to predict two integer \(s,e\) which indicates the answer is \({d_s, ..., d_e}\). \(s,e\) can be found by training two embedding which should be near the target index word's embedding respectively.
3.2. Instruction/Demonstration-Tuning
Dataset (self-instruct) prepare an instruction set in the following manner:
- prepare some seed tasks and input, output instances
- prompt seed task to generate more tasks
- prompt seed task, input, output to generate input/output for the new tasks
- filtering outputs to encourage diversity
See the appendix for the prompt examples
3.3. Reward Tuning
Reinforcement Learning from Human Feedback (RLHF) used in ChatGPT
Model (Human Preference Reward)
Begin with a autoregressive language model \(\rho\), it can be considered as a policy:
where \(x\) is a sequence of input, \(y\) is a sequence of output.
We want to finetune policy \(\pi\) from \(\rho\). If reward function \(r: X \times Y \to R\) is defined , then we can use RL to directly optimize the expected reward \(E_\pi(r)\). However, such a reward function might be difficult to design, so we approximate the reward using human labelings
In this work, we ask humans to choose the best option \(b\) from 4 options \(y_0, y_1, y_2, y_3\), then we fit a reward model \(r\) using the following loss
Then we fine-tune \(\pi\) wrt the reward model \(r\) And also add a penalty to keep \(\pi\) from moving too far from \(\rho\)
The modified reward is
Some related implementation can be found in the TRL repo