0x521 Sequence
Using a standard network model (e.g: MLP model to predict output concats with input concats) to represent sequence is not good, we have several problems here
- inputs, outputs length can be variable in different samples
- features learned at each sequence position are not shared
- too many parameters
2.1. RNN
The Vanilla RNN has the following architecture (from deeplearning ai courses)
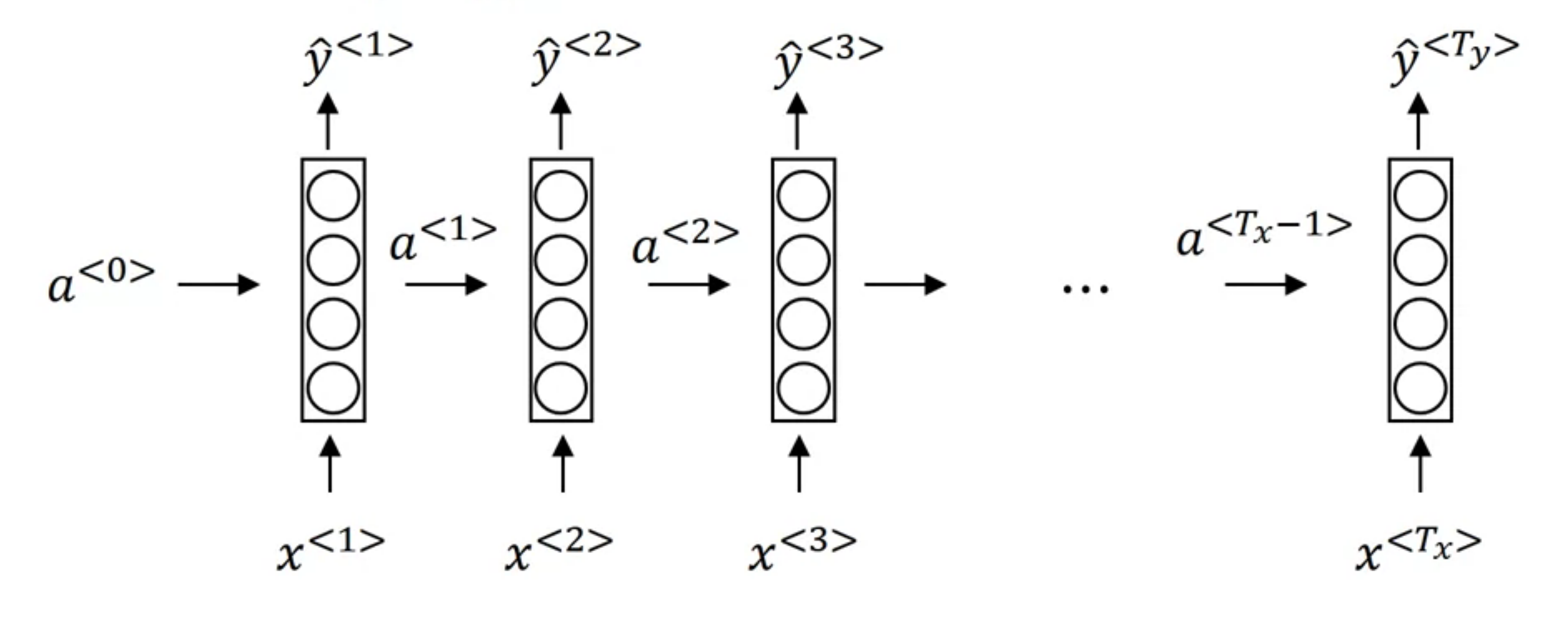
The formula are
2.1.1. Bidirectional RNN
This unidirectional vanilla RNN has some problem, let's think about an example of NER from the deeplearning.ai course.
- He said Teddy Roosevelt was a great president
- He said Teddy bears are on sale
It is difficult to make decision at the word Teddy whether it is a person name or not without looking at the future words.
2.1.2. Gradient Vanishing/Explosion
RNN has the issue of Gradient Vanishing and Gradient Explosion when it is badly conditioned. This paper shows the conditions when these issues happen:
Suppose we have the recurrent structure
And the loss \(E_t = \mathcal{L}(h_t)\) and \(E = \sum_t E_t\), then
the hidden partial can be further decomposed into
Suppose the nonlinear \(\sigma'(h_t)\) is bounded by \(\gamma\), then \(|| diag(\sigma'(h_t)) || \leq \gamma\) (e.g: \(\gamma = 1/4\) for sigmoid function)
It is sufficient for the largest eigenvector \(\lambda_1\) of \(W_{rec}\) to be less than \(1/\gamma\), for the gradient vanishing problem to occur because
Similarly, by inverting the statement, we can see the necessary condition of gradient explosion is \(\lambda_1 > \gamma\)
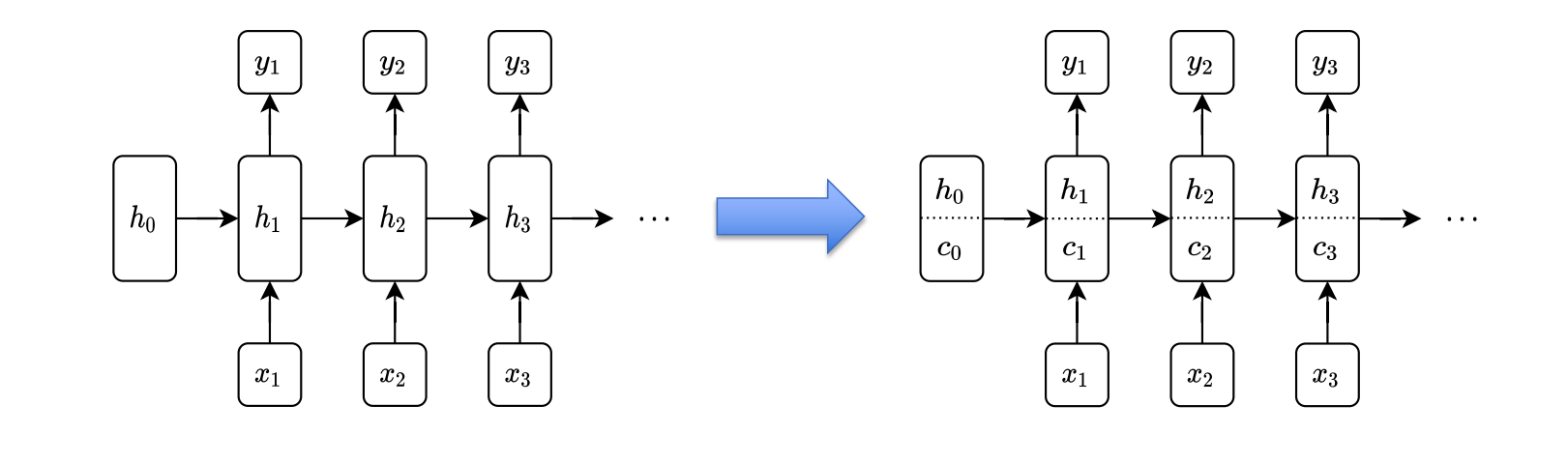
2.2. LSTM
Model (LSTM) Avoid some problems of RNNs
It computes the forget gates, input gate, output gates
The following one is the key formula, where the saturating \(f_t \in [0,1]\) will pass grad through \(c_{t}\) to \(c_{t-1}\)