0x540 Encoder Model
1. Traditional Contextual Models
Model (CoVe, Context Vector) Train the contextualized embedding with supervised dataset (i.e translation)
use the concatenation of GloVe and CoVe as representation for downstream tasks
Model (ELMo, Embeddings from Language Model) Learns the contextualized word representation using a bidirectional LSTM language model.
pretraining
The model is to minimize the NLL in both direction
param (100M)
downstream
After training, ELMo obtains representation by combining hidden vectors from both direction and across all layers with a task specific weight \(w_i\)
Different tasks seem to have different weights across different layers.
contextualized embedding
Topic models and naive embedding models assign fixed embedding or representations to each word. However, the word might have different meaning in different contexts, therefore some recent models are using contextualized representations instead of the fixed embeddings.
The contextualized models usually use generative language modeling or masked language modeling
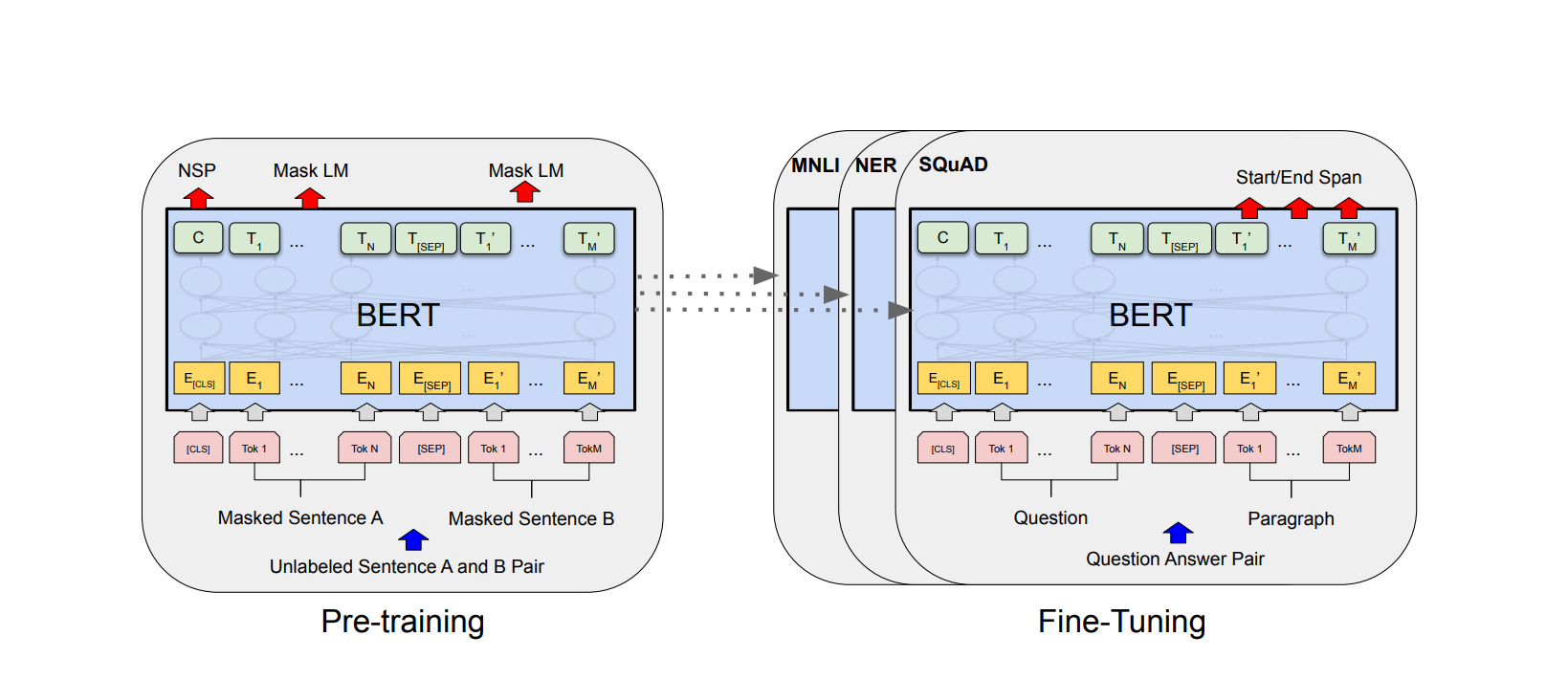
2. BERT
Model (BERT) a multi-layer bidirectional Transformer
Config:
- BERT base: 110M (L=12, H=768, A=12), this config is chosen to be the same size as GPT
- BERT large: 340M (L=24, H=1024, A=16)
number of parameters
A quick way to estimate the order of transformer parameters is \(H^2 \times 12 \times L\), where 4 out of 12 is in QKVO, the remaining 8 is 4+4 in MLP where internal hidden is typically 4 times larger.
See stackoverflow for more detailed computation.
Pretraining
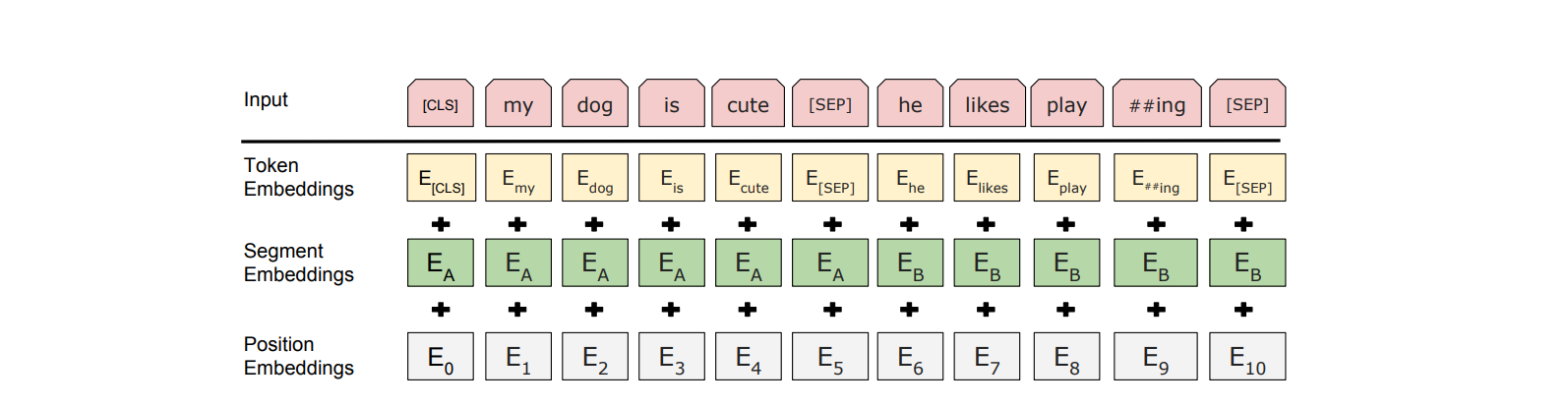
There are two approaches to train bert: Masked LM and Next Sentence Prediction. They are used at the same time.
- Masked LM: 15% randomly mask a word and use other words to predict it. The final hidden of masked words are fed into softmax over vocabulary. cross entropy loss is then applied.
- next sentence prediction: classify whether one sentence come after the other sentence
Model (SpanBERT) SpanBERT is an improvement of BERT by masking span instead of individual tokens
Objectives are
- Span Masked LM: similar to the BERT model but a randomly selected span is masked
- Span Boundary Objective: encourage boundary tokens to predict each word in the span with positional encoding
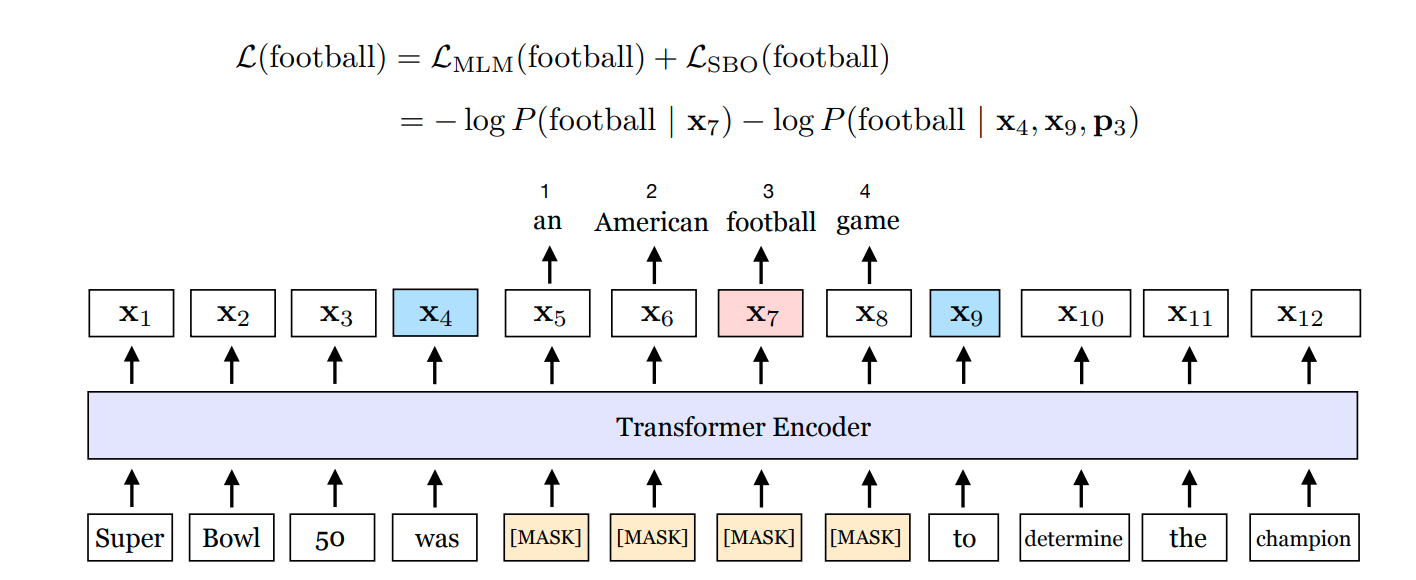 Reference: from the SpanBERT paper
Reference: from the SpanBERT paper
Model (RoBERTa) difference between BERT is
- BERT using static mask (mask are decided during preprocessing), RoBERTa chose mask every epoch dynamically
- each input containing 512 token can be sampled from contiguous sentence with a separator
- next sentence prediction task is dropped
- bigger batch, faster learning rate, bigger training set
3. Cross-Lingual Model
Model (mBERT) Same arch as BERT, but it is trained on the Wikipedia pages of 104 languages
Analysis (mBERT transfer)
- approach: fine-tune mBERT using a specific task in one language, but testing it in another language
- it generalizes well cross-lingual, especially for lexically similar language, but also works for languages using different scripts as well (Urdo written in Arabic, transferred to Hindi written in Devanagari)
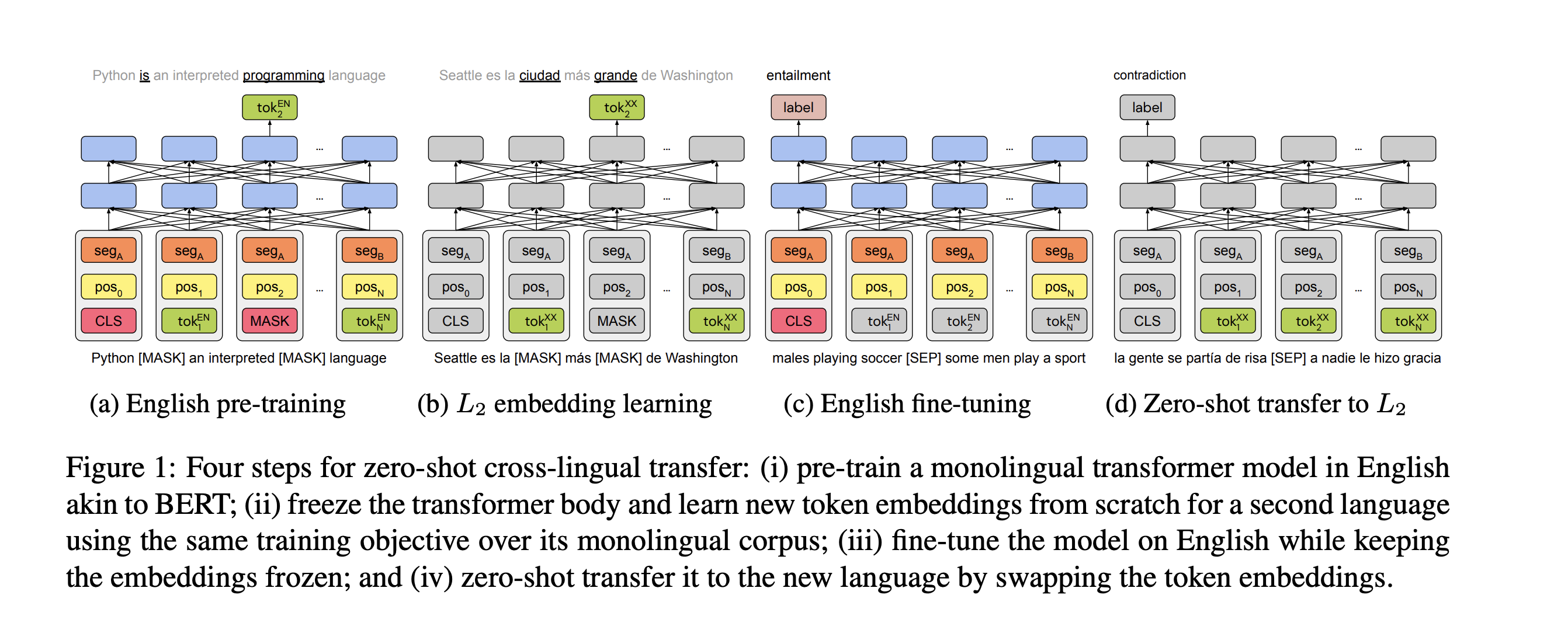
Model (monolingual BERT transfer)
- adapt monolingual bert to a new language by freeze the encoder but retrain the embedding layer
Model (XLM)
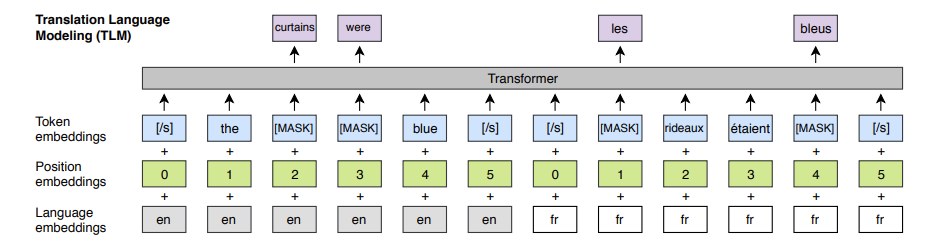
Translation Language Model
- predict a masked English word by attending both English and French, which encourage to align their representations.
Model (adapter-based transfer, MAD-X) using language, task adapters